
Reacting to AI (reducing shadow AI practices)

Getting on top of the latest trend is always fun, but can we make it work this time? While funny/sad pages like https://isaiprofitable.com/ keep popping up, I really wonder: Why can’t we use what we learnt over the last 10+ years in the Kubernetes Ecosystem to double down on platform engineering practices that let teams maximize the use of GenAI?
From my experience talking to community members, platform teams inside large organizations, and consultants in different industries, the key point that all make is that their platform teams are struggling to enable teams requesting more and more GenAI services. Every developer, SRE, DevOps person currently has access to Claude Code, Codex, Copilot among others. This is generating an explosion of tools that can be applied at different stages into the Software Development Life Cycle (SDLC). With more and more agents / services offered for teams to use, platform teams are feeling the heat of supporting a wide range of internal, external and SaaS services that solve very specific problems.
To be honest, this is nothing new. Every platform engineering presentation that I’ve seen in the last three years makes reference to the CNCF ecosystem, which we used to explain how hard it was for teams to keep up. The problem has now been multiplied hundred times.
Dealing with Multi-Agent distributed Systems
Let me put on my practical hat, and let's be concrete. We are experiencing first hand the journey for hyper-automation. We are not talking about tools for GitOps, Security, Observability. We are talking about “autonomous” agents that perform very specific tasks. In general, one of the main characteristics of these agents is that they use GenAI to evaluate the context and produce an output. Examples of these agents are extremely popular these days:
- Coding Agents: such as Claude Code, that based on a prompt will produce code
- Pull Requests Review Agents: that review the code proposed in a PR and provide feedback, comments or automatically reject
- SRE Agents: that monitor a Kubernetes Cluster and can help SRE teams to troubleshoot issues
- Business Agents: agents that deal with customer requests, for example a chatbot that is connected to internal systems and can answer business requests.
I am pretty sure that platform teams didn’t ask for Claude Code to be given to all the organization developers, but platform teams are the ones responsible for making sure that accounts are managed, keys can be distributed and (if you are lucky) some reports about usage are generated.
We have reached a point where there is no way out, platforms need to rise to meet the demand of all these new workloads, which in most cases are far from our production environments. Some of these agents might run on Kubernetes, but some of them will run on your CI infrastructure (GitHub, Gitlab), some will run on each developer laptop, pushing your platform initiatives way outside of Kubernetes and your cloud provider accounts.
Another by-product of adding all these agents to the SDLC is that the shape of what it means to deliver software is mutating. If we are hyper-automating every step of the SDLC, human involvement and intervention shifts. This great article by Joe Kutner from Saleforces/Heroku makes it clear, our old SDLC was created for humans, so it must change now that we have agents.
But, Why?
Automating just for the sake of automating, usually doesn't make sense. But automation always sounds nice, as it is commonly associated with saving money. I am quite happy to see that the industry is slowly aligning on a taxonomy/terminology about what we want to achieve.
Blog posts like this one from Dan Shapiro’s early this year are resonating hard in the industry as they start hinting at a concrete plan for what agents, but most importantly platforms will need to evolve. Dan’s blog post uses autonomous self-driven cars as an example which creates a perfect analogy for what your platform needs to be prepared for.
The goal: to build autonomous software factories.
The role of your platform: connect all the agents, internal systems and provide contracts that agents, humans and operators can use to operate the autonomous factory.
How?
To build such autonomous systems, you need to build strong foundations that agents and humans can use to drive things forward. Having a set of levels to gauge where your organization currently is, is extremely helpful to plan what your next move will be.
You will find these levels with different names and with slightly different descriptions, but it feels like we are getting close to some sort of industry-wide agreement.
Here are the five levels of Agentic Engineering that I see the industry is starting to align with:
- Level 1 - GenAI Assisted: agents assist the user by providing alternatives and suggestions, the user drives the interaction and accept or reject suggestions. There are two examples that clearly resonated with me Grammarly and IDE auto-completion based on GenAI models.
- Level 2 - GenAI Augmented: agents generate code, perform a task, the human needs to review the output. Tools like Claude Code, Codex, and tools like Cursor fits this level quite nicely. The question that most organizations are starting to ask is around how do they can manage all these tools using a platform approach.
- Level 3 - Spec-Centric: agents generate and modify resources, but also review and provide proof/validation of behavior (tests reports, screenshots, etc) so the human only reviews intent, not line by line diffs. Specs need to be written to define intent and how it needs to be validated. This is closer to defining business requirements. Agents need to understand architecture, conventions and style that goes beyond a single repository. When you start writing specs, you need to go down to specific technology choices, so agents know what is off limits and what decisions have already been made.
- Level 4 - Selective Autonomy: based on existing data (from previous executions in similar contexts) agents can make decisions on their own to move things forward autonomously in the SDLC. Agents can check and have clear guidelines to when they are authorized for example to approve and merge a pull request. At this level, a trust model needs to operate at the platform level to progressively let agents be more autonomous. To build trust models the big challenge is to collect and summarize data about previous executions, so agents can use evidence to make grounded on data decisions. Humans still need to handle escalations and override agents when things go off rails.
- Level 5 - Full Autonomy (Dark Factories): humans provide specs, agents produce, review and ship changes. Humans intervene to improve the factory when failure emerges. Agents notify humans, but don’t ask for permission. It feels impractical to talk about this level as most teams are trying to progress from Level 2 to Level 3.
As you can see the level of sophistication required to move from level two to three is what is stopping organizations reaping the benefits of autonomous agents.
Unfortunately, to move from one level to the next, you need to fully master the previous level, as each level builds heavily on the previous one.
So what does this mean for our platforms?
If your platform already took care of packaging applications CI, CD with GitOps, security, observability you are well positioned for further automations. If you are already using DORA metrics to measure how your teams are performing you are in a really good spot. If you are not there yet, it is time to double down the investment on core infrastructure for your platforms, as highlighted by the DORA report on AI ROI.
Imagine that your developers are already generating code with tools like Claude Code, or that you can do automatic code generation from looking at issues descriptions. As teams have increased agentic generation of code, the review phase is still manually handled by humans, they are hitting a bottleneck. Adding agents to review your pull requests might be the next step for you but it will be clearly not the last one.
From GenAI Augmented to Spec Driven (L2 -> L3)
Your platform needs to understand what the intent of the change was being introduced so it can validate its behavior.
From a customer request ticket it needs to be able to validate that the change is not only correct at the code level, but at the behavior/intent level too.
By using GitOps tools like Flux CD or Argo CD, the creation of preview environments to validate changes is something that platform teams have automated already. The big shift here is to perform automated validations using specialized agents that by reading the issue description and proposed fix can validate the fix in a preview environment. I’ve seen companies using tools like vCluster to make preview environments (which are most of the time ephemeral) cost efficient.
Notice that for this flow to happen, the platform should already provide a set of mechanisms that set things up for agents to use and perform validations. Notice how different is to let agents use your existing platform constructs, compared with creating agents to use low-level APIs in a non-deterministic way to implement complex flows.
Implementing different release strategies at this stage might be also a good idea to perform deeper validations that might require live traffic or A/B testing. Using tools like Knative Serving or service meshes like Istio or Linkerd play a fundamental part of how platforms can enable this more complex validations.
Fine tuning this process is hard, and only by mastering this loop can you move forward to Level 4.
Before jumping to Level 4, there are two things that I would recommend platform teams to do to build a solid Level 3: Measuring the impact and dealing with non-determinism at the platform level.
Measuring the impact (DORA)
Generating, validating and making sure that changes follow all the way through production is expensive and time consuming. If the changes that we are making in favour of automation are not improving our delivery practices, investment funds will run out.
That is why I strongly recommend checking the “DORA: ROI of AI-assisted Software Development report” which helps organizations to plan for the AI tuition tax.
Organizations should expect a dip into their software delivery pipelines while adopting new tools. This usually materializes in a speed up on deployment frequency which is compensated by an increased failure rate. We are pushing for speed and we get instability in return.
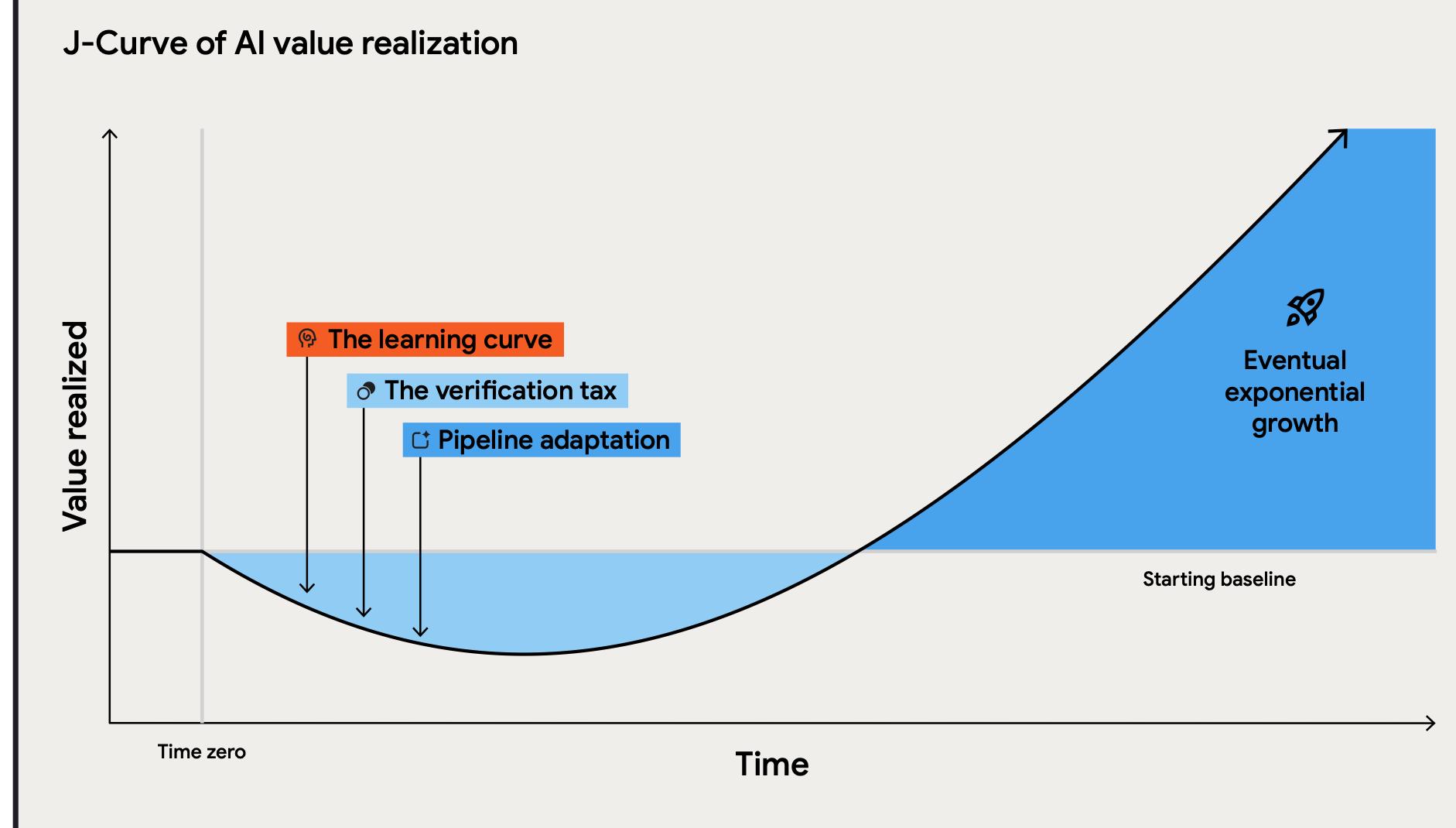
But once again, in order to see what is going on, we need to observe/record way more than our production environment. We now need to ingest data from our delivery pipelines (CI/CD, preview environments), from our source version control platform (Github Issues and PRs, for example) and our customer support tickets.
Understanding the impact of AI adoption, follow similar patterns as adding any new tool to our stack. Without having hard data to compare, you are operating in the dark.
Dealing with non-determinism, a platform play
Quality stills matter. Every generated change that ends up in a Pull Request, will go through an expensive (resources and time) pipeline before it hits your customers, hence making sure that changes gets validated before pushing them through is a new platform concern.
Organizations have myriads of models to choose from and it is becoming a standard pattern to choose the best model for a given task as well as reviewing generated code from one model using another one.
To reduce cost and optimize resources, platforms need to provide golden paths to simplify these checks and evaluation loops. Developers shouldn’t worry about these checks and as mentioned before, validation can happen at a higher level (intent), but with a detailed technical report about which evaluations were executed for a given change.
A concrete example of a platform capability that a platform should provide is model selection based on previous performance or benchmarks. You can use external benchmarks or benchmarks based on data that you collect from previous code generation or previously executed tasks. To collect data, you can enable as a platform capability to run agents using different models for a given task (for example code generation for a given issue) and then use platform services to evaluate which performs better. While this is more expensive to start with, in the long run you will have enough data to make the right choices based on the tasks that your platform is performing more often.
From Spec Driven to Selective Autonomy (L3 -> L4)
In this scenario, to approve changes automatically means that you trust your validations/evaluations to be good enough to not impact your customers.
To build trust across your autonomous agents that the resources that they are managing (code, services, environments), you need data.
The only way to build trust is to record previous approvals, but also to measure how these changes are affecting your customers' experiences. This requires being able to confidently say that your evaluations have been consistent for a set of services that your organization is ok to be driven by these agents.
The human involvement shifts from approval to trust validation. Where the task of the operators is to review the trust gates for services to be shipped and handle escalations when they happen.
From Selective Autonomy to Dark Factories (L4 -> L5)
The ultimate goal is to build a set of agents that can produce and ship new features, fixes bugs in a completely autonomous way. This level of sophistication requires a strong platform, a strong harness and a lot of data that needs to be used to make continuous decisions as new scenarios need to be managed.
The first players to build these advanced solutions will be the ones heavily invested in providing GenAI services. Claude Managed Agents, OpenAI Frontier, AWS Bedrock Managed Agents, Google Gemini Agents Platform, the Langchain ecosystem, Crew AI, among others are paving the way in terms of requirements, developer experience and expectations.
Following the same approach to build our internal platforms to manage and operate distributed multi-agent enabled SDLCs is not a bad idea.
My experience in the tech industry tells me that these managed platforms aim to target 70% of the use cases, while most large organizations will struggle to re-platform their existing solutions to these new breed of managed services.
Similarly to what happened with Cloud Providers, when organizations go over acquisitions, mergers it will be quite difficult to escape a world where multiple of these managed platforms will need to co-exist and integrate. Keeping an eye on the standards that these platforms use, or to put it in another way, the decisions that they make to platform sticky are the core things to look out for.
Don’t Panic
As platform engineers we are now in charge of a fleet of agents, running all across our software delivery pipelines. We need to deal with how these agents access different models/services and make sure that these agents get the best model for the work that they are doing. In some ways, the platform is responsible for the output of these agents, as the platform must provide the validation/evaluation mechanisms to guarantee that agents are not going off the rails.
But, we have the tools, and the learnings from the Kubernetes, Cloud Native and Platform Engineering ecosystems. We know how to extend Kubernetes to support GPUs and host LLMs, we know how to efficiently create preview environments and do very advanced GitOps workflows, we know how to observe distributed systems.
The next layer on top of Kubernetes that we need to build, is the learning layer. To be able to learn, you need to record information and synthesize durable knowledge. If all these agents use the same standard format to export agents' telemetry (such as the OpenTelemetry GenAI Semantic Conventions) this new layer can benefit from a huge ecosystem of components already using this format.
It is important to recognize that agentic engineering is not Kubernetes-first, agents will run inside and outside of our Kubernetes clusters and our platforms need to cater to both.
If you come from the Cloud Native ecosystem, you are trained to recognize the patterns and the tools to solve specific challenges. My recommendation today is to focus on unification, specs and standards.
As a practitioner, I am looking at what cloud providers and AI providers are building. I am taking notes and mapping the tools that we have in the cloud native ecosystem to help organizations to reuse the infrastructure we already have. GenAI providers are running LLMs on Kubernetes, they are running their managed agent platforms on top of Kubernetes.
As we learned from cloud providers, organizations can go that far only relying on cloud provider services. They need to build their internal practices, pay the AI tuition tax and at the end of the day build their internal platforms that adapt to their structure and operations.
As always, if you are working in this space and seeing similar things, do get in touch. I would love to collaborate with people building tools and pushing standards forward.