
RFC: Activiti Cloud Application Service
When you build distributed architectures (with containers involved), applications end up being a set of logically related microservices that you run on top an infrastructure. This infrastructure will allow you to set up isolated environments where you should be able to control resource allocation and security. We believe that inside each of these environments you might want to have a set of these logical applications, which means that you will probably have a lot of containers deployed. Some of these containers will be infrastructural services, such as Data Stores, Message Brokers, Gateways, and some of them will be very domain specific.
The main responsibility of the Activiti Cloud Application Service is to provide this high level (Activiti Cloud specific) view of a set of domain specific applications that are running inside an environment. At some level Applications also provide isolation between each other and they usually require different Role Based Access Control, IDM configurations, different message broker configurations, different set of credentials, etc.
The purpose of this document is to serve as a specification for the initial implementation of the Activiti Cloud Application Service which serves as some kind of controller/monitor for the Applications that are deployed inside our Cloud Native environments. This can be used by client applications to consume and interact with each Application Services.
Notice: even if we are targeting Kubernetes we need to make sure that the core service is technology agnostic. This is, as in any service of community project needs to rely on common abstractions, trying to reuse existing ones or collaborating with existing communities to avoid duplication of effort.Features
The Application Service endpoints should expose the available applications, the application metadata and the application state. The Application Service should not store this information, but rely on delegating as much as possible to the Service Registry, Configuration Service and other services in the infrastructure.
The Application Service is not responsible for deploying/provisioning new applications, but it should expose operations such as the structure and status of the application to understand when applications are already provisioned and ready to receive requests. This means that for at least the initial version of this service most of the operations will be READ only. This service should react to changes in the environment (new service registration/de-registration) to make sure that the Application Service is providing data that is up to date and reflecting the real status of the deployments, this can be achieved by monitoring the Service Registry.
The Application Service should also interact with the Configuration Service to understand each application and its infrastructural services configurations and dependencies. For example: if Runtime Bundle (one of our core building blocks) depends on a Relational Database and a Message Broker, it can look into a Configuration Service (or configMaps) for an entry related to the application service to understand which infrastructural services are required for the application to run. We can be smart and list these requirements before deployment time, so an administrator can make sure that those infrastructural services are ready.
Applications have a relationship with IDM and security, because we are using Keycloak as our SSO and IDM provider, Applications might require to have a different realm configuration.
A key important feature that must be considered and analyzed is Applications versioning. Making sure that we can move applications from different environments and that each of these Application will have a lifecycle is important. The intention of this document is to describe these aspects, but not to solve them all.
Interactions / Flow
The following diagram shows the components that will interact to provide the features described above:
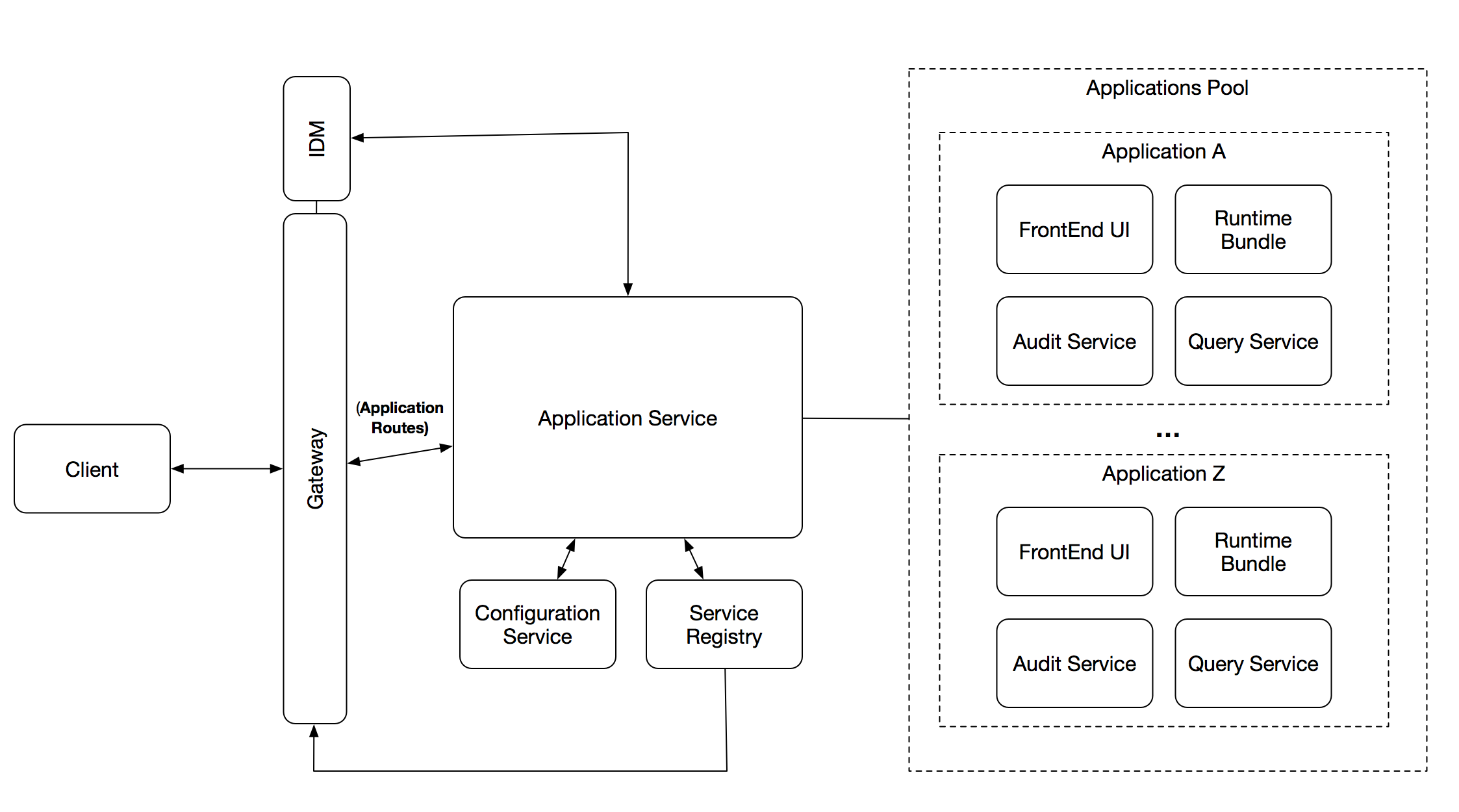
The Application Service has relationships with 4 key components:
- Configuration Service (ConfigMaps in K8s and Configuration Service in Spring Cloud)
- Service Registry (Eureka outside of K8s and the K8s Service Registry)
- Gateway (Spring Cloud Gateway)
- Identity Management / SSO (KeyCloak)
In order to provide these high level abstractions (one application composed by a set of services) we need to have an Application Deployment Descriptor, which basically describe the Application expected structure. This Deployment Descriptor describes how the application is composed and implicitly define what is required for the Application to be UP (state).
For this reason, the first step of the interaction is to create this high level Deployment Descriptor. This high level Deployment Descriptor maps the Activiti Cloud Building Blocks (Runtime Bundles, Cloud Connectors, Query & Audit Services, etc.) to an Application structure.
This Deployment Descriptor will live inside the Config Server, which has a structure to store Deployment Descriptors in a directory fashion. In other words, the Deployment Descriptor Directory will have a list of Application Deployment Descriptors available, that can be queried to obtain references to the available Deployment Descriptors for Applications.
This Deployment Descriptors will be used to match against the Service Registry the status of each Application.
Each Service provisioned will require to have two pieces of MetaData that will allow the correlation against these Deployment Descriptors:
- Activiti Cloud Application Name
- Activiti Cloud Service Type
If these two pieces of information are added to the Service Instance information inside the Service Registry, the Application Service will be able to correlate, validate and monitor the relationship between the services that are currently deployed.
Notice that all services that doesn’t belong to an application, will be grouped together.
The Application Service then, will be in charge of interacting with the Service Registry to answer questions about the amount of deployed applications and their respective state.
The sequence of interactions is as follows:
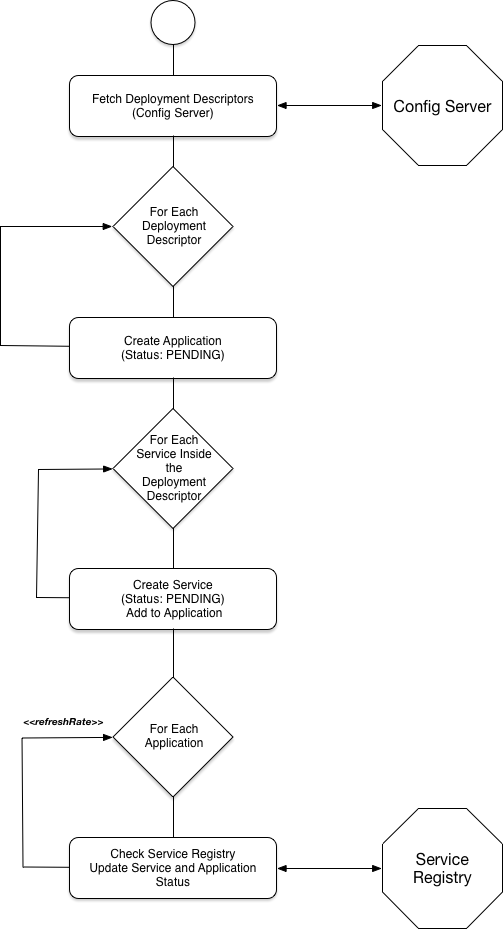
It is important to notice that there is no state storing as part of the Application Service, all state is created based on the Deployment Descriptors in the Config Service and based on the currently deployed services in the Service Registry.
Data Types
As the first Draft of the service the following Data Types are going to be introduced.
These entities and data types should be agnostic to the underlying implementation. These Data Types represent our view of the world when we think about Activiti Cloud Applications, and we shouldn’t assume any particular implementation or technology stack.
- ApplicationDeploymentDirectory
- ApplicationDeploymentEntry[]
- DeploymentDescriptor
- applicationName
- applicationVersion
- serviceDeploymentDescriptors[]
- Name
- Version
- ServiceType
- Application[]
- Application
- Name
- Version
- ProjectRelease
- Realm (Security Group / IDM bindings)
- Status
- Services
- URL (path??)
- Configurations[]
- Resources[]
- ServiceType
- Name (Descriptive name)
- ArtifactName (artifact - maven / docker image)
- Version
- Status
- Application
- ServiceType -> Enum: (Connector, Runtime Bundle, Audit, Query, Domain Service)
- ProjectRelease (Coming from Modeling Service)
- Status (UP, DOWN, PENDING, ERROR)
- Realm (TBD)
Proposed Endpoints
- GET /v1/deployments/directory -> list of applications that we want to deploy (static)
- GET /v1/deployments/{deploymentName} -> get deployment descriptor for a given app
- GET /v1/apps/ -> list of APPs names and link to app
- GET /v1/apps/{appName}/ -> get app info
- GET /v1/apps/{appName}/services
- GET /v1/apps/{appName}/services/{serviceName}/url
- GET /v1/apps/{appName}/services/{serviceName}/config
Evolution, Versions Upgrade and Data Migration
If we are considering applications to contain Runtime Bundles, we need to define how these Bundles evolve into future versions and how the version of the application relates to the Runtime Bundles in it. Runtime Bundles were conceived as immutable containers for sets of Runtimes, not necessarily and not only Process Runtimes.
We need to define some common scenarios of how this is going to work making sure that we cover a wide range of scenarios. Traditionally in BPM platforms there are some different scenarios that you want to cover:
- Migration between different versions of the same process definition: this opens the door for a lot of complications like for example: what happens if two process versions are completely different, and migration of in-flight processes is not possible at all? It also introduces the concept of manual migration, where each individual instance needs to be inspected and migrated manually.
- Running two different versions of a process definition in parallel, until the old version doesn’t have any more in-flight processes, this is usually a good approach to make sure that things cannot go wrong, but it forces us to think about the routing logic used to create new process instances. *It is interesting thing to notice that this is a more aligned approach with the concept of immutability*.
- Sometimes, no matter what you are doing you just want to deploy a new Application version, and forget about the old one, including data. This is quite common on development cycles. Basically you want to throw away your current version of the application and replace it with a new version without really caring about data migration. If you want fast iteration cycles this might be required.
Based on these categories the following strategies are suggested:
- Maintain: use the same data store and add new versions of process definitions, keeping the old ones in. This will require some enforcement at the time of creating new versions of the existing Runtime Bundle.
- Migrate: a set of operations will need to be executed when rolling an upgrade, endpoints should be provided for inflight process extraction and injection. This strategy will be very useful for situations when we want to move executions from one environment to another, where the underlying data store is not the same and data need to be moved.
- Parallel: You want to run the previous version of the inflight processes in the same Runtime Bundle where those were defined and start running the new version in parallel in a different Runtime Bundle instance. A routing mechanism will be needed and a retire policy might be required to check when to shutdown the old version.
- Destroy: You want to throw away the old definition and just run the new one. You don’t care about data that was generated by the old version.
Notice that these strategies should be defined at application level, not at Runtime Bundle level, because these strategies will impact other components such as Audit and Query. The consistency needs to be maintained at Application Level.
Each strategy will implement a different flow of actions (pipelines) that should be automated or triggered by a DevOps user. Notice that no reference to any pipeline should be included in this service, but hooks should be available.
(TBD Strategies examples and planning for implementation, suggestions and comments are more than welcome)
Other topics / Risks / Open Questions
We are building the Application Service because we have some Activiti Cloud specific requirements, but the Kubernetes, Spring Cloud and other communities (like JHipster) are looking at these requirements using different angles. As part of the development of this service, we commit to monitor these communities and collaborate with them to make sure that we do not duplicate any functionality, instead we will collaborate and improve what they propose to benefit all from the same set of core libraries and infrastructure.
- Kubernetes Service Catalog ( https://kubernetes.io/docs/concepts/service-catalog/ )
- Spring Cloud Open Service Broker ( https://github.com/spring-cloud/spring-cloud-open-service-broker )
- Kubernetes Application Kind proposal
- Spring Cloud Deployers SPI (where Apps are just single spring boot apps) -> https://github.com/spring-cloud/spring-cloud-deployer
Notice because of the interaction between the Service Registry and the Configuration Service, for Spring Cloud pure apps, we can bundle the Service Registry and the Configuration Service together as other communities are doing (http://jhipster.tech/). Following the same approach we can also bundle the Application Service with these two to avoid extra containers to be deployed.
When we look at K8s, this means that we will need to have a container for the Application Service which will interact with the K8s Service Registry and Config Maps, raising the question if we can bundle this service with the Gateway container.
Some research should be done around the relationship between our ApplicationDeploymentDescriptors and the real deployment descriptors such as Kubernetes Deployment Descriptors (YAML files) and HELM Charts. It is important to have a trace between the Activiti Cloud view and the real deployment descriptors that are used to provision the services. For this reason, looking into Monocular ( https://github.com/kubernetes-helm/monocular ) and the relationships between the services explained here is important. It is also important to make sure that we follow similar practices for dealing with versioning and releases as HELM or similar technologies which are already designed to solve these scenarios in a non BPM specific way.
References
Github Issues:
https://github.com/Activiti/Activiti/issues/1692
Incubator Project:
https://github.com/Activiti/incubator/tree/develop/activiti-cloud-application-service
Original Document in Google Docs open for Comments:
https://docs.google.com/document/d/1ZKKJQIXu313ak9lUzsfj46bZbQRzqe1zPrPVpM98hlU/edit?usp=sharing