
RFC: Java Process & Task Runtime APIs
The main goal of this document is to create a proposal for a new set of Process & Task Runtime oriented APIs. This APIs will be provided as separate maven modules from the activiti-engine module, where the interfaces defined in the APIs will be implemented. The main purpose for this new API is to make sure that the path to the cloud approach is smoother, allowing implementations to start by consuming the framework and then move smoothly to a distributed approach. As mentioned by Martin Fowler in his blog post Monolith First, https://martinfowler.com/bliki/MonolithFirst.html we are going through an evolution to better isolation to support scalable and resilient architectures. The API proposed here are consistent with modern development approaches, compact and making sure that the transition to a microservice approach is faster and conceptually more aligned.
Until now, the Activiti Process Engine was bundled as a single JAR file containing all the services and configurations required for the engine to work. This approach pushes users to adopt all or nothing. Inside this JAR file there are interfaces and implementations which are tightly coupled with the Process Engine internals. This causes maintenance and extension problems of different implementers not understanding where the public API ends and where the internals begin. This also blocks the Activiti team to move forward and refactor the internals into a more modular approach.
It is really important to notice that the old APIs will not be removed, but the new APIs will be always the recommended and maintained approach for backward compatibility.Process Runtimes are immutable runtimes that knows how to execute a given set of business process definitions (concrete versions). Process Runtimes are created, tested, maintained and evolved with these restrictions in mind. Process Runtimes have a lifecycle, they can be created and destroyed. It is likely for a process runtime to be included in a pipeline for making sure that the Process Runtime will work properly when needed. In other words, we need to make sure that Process Runtimes, after its creation, will work properly based on the acceptance criterion defined.
It is also important to note that Process Runtimes provides you the granularity to be scaled them independently. In contrast with the notion of Process Engine, where you never know the nature of the Processes that you will have in there and hence testing, validating and defining scalability requirements becomes a painful (if not an impossible) task.
In the same way the Task Runtime will provide access to Tasks. Once the Task Runtime is created we can expect the same behavior (and configurations) to apply to every task created by this runtime.
One more important difference between the old notion of Process Engine and Process Runtimes is the data consumption aspect. Process Runtimes are designed to execute Processes. Task Runtimes are designed to execute Tasks. Process & Task runtimes are not designed for efficient querying, data aggregation or retrieval. For that reason the Runtime APIs will be focused on compactness and the execution side. Following the CQRS pattern (Command/Query Responsibility Segregation, https://martinfowler.com/bliki/CQRS.html ) the Runtime APIs are focused on the command (execution) side. There will be another set of APIs for efficient querying and data fetching provided outside of the scope of the Runtime APIs. Check the Activiti Cloud Query Service for more insights about these APIs.
Main Constructs (APIs)
While creating the proposal, we have the following architectural diagram in mind. You can consider this as the ultimate objective from an architectural and APIs point of view:
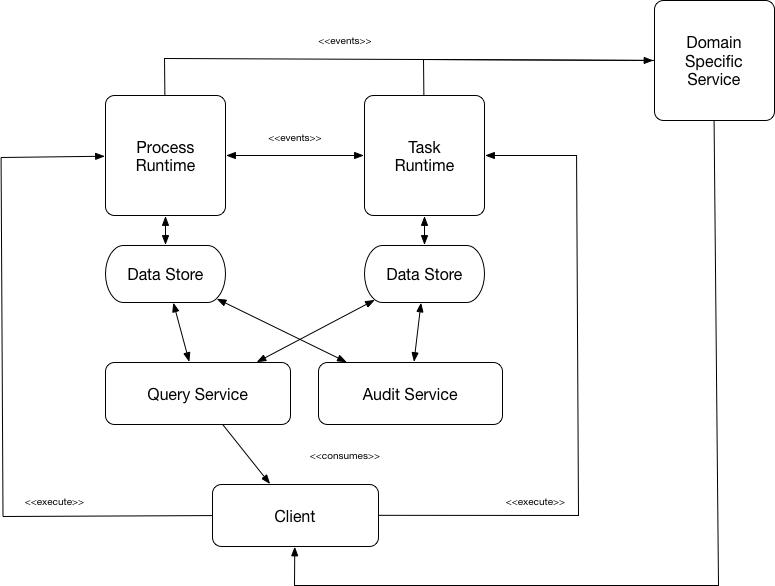
We want to make sure that there are clear limits and separation of concerns between the different components exposed in our APIs and for that reason, even if we cannot fully decouple the internals right now, we want to make sure that our APIs clearly state our intentions and motivations for future iterations.
ProcessRuntime
- processDefinitons() -> Immutable list
- processInstances()
- operations(Create/Suspend/Activate)
- metadata()
- signals()
- users()
- groups()
- variables()
- processInstances() -> get all the process instances that are in this Runtime (quick accessor to bypass the selection of the process definition)
- Operations
- Activate
- Start
- Delete
- Suspend
- Operations
- Operations (broadcast and batch to all process instances)
- signal()
- stats() / info() // The statistics and status of the Runtime
- configs() -> configurations used to create the Process Runtime
- destroy()
TaskRuntime
- Operations
- create()
- complete()
- claim()
- release()
- update()
- configs() -> configurations used to create the Task Runtime
- destroy()
RuntimeConfiguration
- eventListeners()
- connectors() - > system to system connectors (old JavaDelegates)
- dataStore()
- policies() // security policies for process definitions
- identity()
- getGroupsForCandidateUser()
EventListener
Connector
- health()
- stats()
Events
- Events emitted the process runtime
- ProcessInstanceCreated
- ProcessInstanceStarted
- ProcessInstanceCompleted
- ProcessInstanceSuspended
- ProcessInstanceActivated
- ProcessVariableInstanceCreated
- ProcessVariableInstanceUpdated
- ProcessVariableInstanceDeleted
- Events emitted the task runtime
- TaskCreated
- TaskAssigned
- TaskCompleted
- TaskReleased
- TaskUpdated
- TaskSuspended
- TaskActivated
- TaskVariableInstanceCreated
- TaskVariableInstanceUpdated
- TaskVariableInstanceDeleted
Maven Modules
The separations of concerns between Tasks and Processes at the API level will be kept in separate packages. Providing an activiti-process-runtime-api and a activiti-task-runtime-api. These packages will represent our Backward Compatibility Layer with clear deprecation and evolution policies.
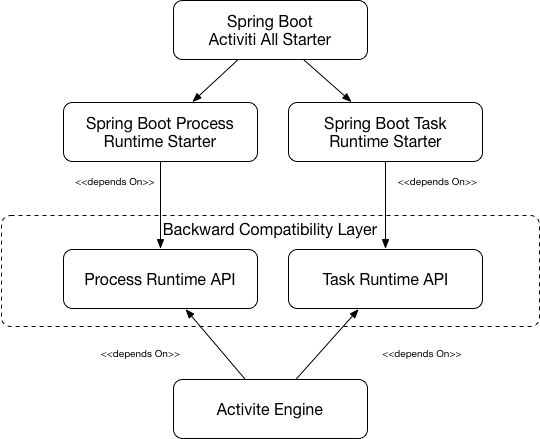
For Spring Boot users the Spring Boot Starters will provide all the configuration and wiring needed for quickly get a ProcessRuntime and a TaskRuntime up and running.
Developer Scenario
- The developer is working in a Java Application with Spring Boot
- The developer adds the activiti-all-spring-boot-starter dependency
- The developer uses only interfaces in the activiti-process-runtime-api project to interact against Process Runtimes
Maven dependency:
<dependency>
<groupId>org.activiti</groupId>
<artifactId>activiti-all-spring-boot-starter</artifactId>
</dependency>
Configuration wise the following types will be autowired (following standard spring practices: aka autoconfigurations) for you while creating the ProcessRuntime instance:
- EventListener
- Connector
This autoconfigurations should match the available metadata from our process definitions to make sure that our processes has everything required to run.
Then you should be able to do:
@Autowired
private ProcessRuntime processRuntime;Now you have a ProcessRuntime available in your application, this ProcessRuntime object will be populated with the available process definitions in the classpath. This means that this ProcessRuntime instance can be heavily tested for that set of process definitions.
With the new processRuntime instance you can access to the available processDefinitions:
List<ProcessDefinition> processDefs = processRuntime
.processDefinitions();Notice that there are is no way to change this list of ProcessDefinitions. It is an immutable list.
You can get the configurations used to construct this ProcessRuntime by doing:
ProcessRuntimeConfiguration conf = processRuntime.configs();Here you can check which connectors and event listeners are currently registered to your runtime. In particular, getting connectors informations is a key improvement over previous versions:
Map<String, Connector> connectors = processRuntime.configs().connectors();This allows Process Runtimes to validate at creation time, that all the Process Definitions loaded can be executed, because all the connectors required are present.
In a Spring context, all connectors and listeners will be scanned from the classpath and make available to the Process Runtime at creation time.
To create process instances it should be as simple as selecting the Process Definition and creating new instances with our fluent API:
ProcessInstance processInstance =
processRuntime.processDefinitionByKey(“myProcessDefinition”)
.start();And then actions:
processInstance.suspend();
...
processInstance.delete();Getting Process Instance should look like:
List<ProcessInstance> instances = processRuntime.processInstances();Or
ProcessInstance instance = processRuntime.processInstanceById(id);Task Runtime should follow the same approach as Process Runtime:
@Autowired
private TaskRuntime taskRuntime;
…
Task task = taskRuntime.createWith()...;
task.update();
task.complete();The initial version of these APIs will be restricted to the minimal amount of operations to cover most use cases. Are you using Activiti 5 or 6 APIs? We will appreciate community feedback on what other features not mentioned here are you using in your projects?
Other Considerations and References
Reasons to introduce a new set of APIs:
- Making sure that we have a clear line between internal code and external APIs that we suggest users to use and rely on for backwards compatibility
- A reduced technical surface that is nicely crafted and achieving a single purpose.
- A well defined set of interfaces to avoid all or nothing approach. Improved transitive dependencies control over our microservices and clear separation of concerns
- Closely aligned with Cloud Native practices for easy transition to distributed architectures
- Provide more freedom to refactor internals into a more modular and maintainable approach
- Leverage new reactive frameworks and programing practices
PoC in Incubator (to track the progress)
https://github.com/Activiti/incubator/tree/develop/activiti-process-runtime-api
Feel free to add comments to our live RFC document here:
https://docs.google.com/document/d/1S9KDOoFTkbjwPq6LWEKVPLP5ySJJgoOX1ZIsZcdPi-M/edit?usp=sharing