
The Challenges of Platform Building on Top of Kubernetes 2/4
As a continuation to my previous blog post that you can find here, this one goes deeper into the wide range of infrastructure that our Internal Development Platform (IDP) might need to cover and how tools like Crossplane, VCluster, and Knative can help. Specifically, after covering the basics, I wanted to spend some time talking about VCluster Plugins, not so much about what they can do today but more about how the approach can become core to platform building, efficient use of tools and resources across multiple Kubernetes Clusters.
Here you can find the slides from the Loft Meetup in London. I will share the video as soon as it is up on youtube.
[slideshare id=253269884&doc=creating-platforms-loft-meetup-london-220930054445-7512cd44]
Platform Topologies
Ok, if your platform will expose a set of APIs and implement custom behaviors (like the example discussed in the previous blog post), we need a place (servers) to run these components. If we are going to automate some work using CI/CD tools, we need a place to install and run these tools. As you might have guessed, these tools cannot run with (in the same clusters as) our applications. The last thing we want is our Continous Integration (CI) tools to battle for resources against our applications serving our customers' requests. For security reasons, we want to ensure that if our CI tools or automation tools have security bugs, our applications cannot be taken down as part of an attack on these tools that are not directly being used by our applications.

It becomes clear that if we have platform-wide tools and separate environments when we translate this to Kubernetes clusters, one Kubernetes cluster will not do the job.
To provide enough isolation between the platform tools and the environments where the application will run, we need to be capable of running a multi-cluster setup.
A simplistic view would be to have a Cluster for platform-wide tools and separate clusters for different teams to work on, including shared environments such as Production and Staging.
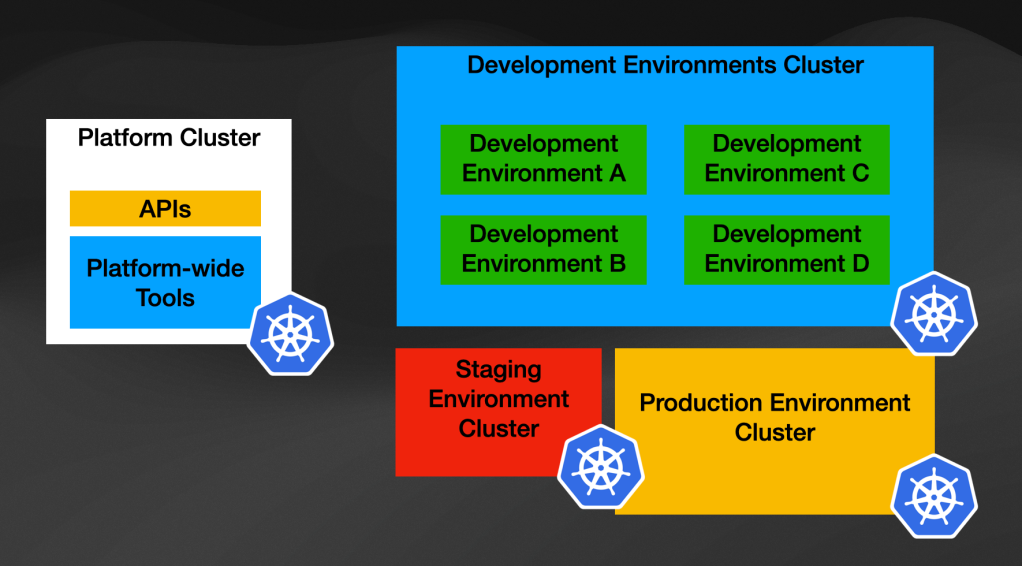
Having a fixed number of clusters is complicated on its own, so you can imagine a dynamic platform that allows people to create these environments on demand will be complex. Organizations have experimented with enabling developers with their own infrastructure (in this case, their own cluster) and opinionated workflows around how they can request these environments for doing their work. I recommend you read the article about how Stripe (Payments platform) enables their developers to go faster by creating multiple environments per developer (Stripe's DevEnvs infrastructure article). If you translate this kind of scenario to Kubernetes, you will need to be able to provision new Kubernetes Clusters on demand.
The need for dynamic multi-cluster setups
Sooner or later, if you are working with Kubernetes, you will have a separate cluster (or clusters) in charge of hosting “the platform components and tools” and other clusters running your application workloads and your development environments. The closer these environments are to your production environment, the sooner and easier it will be for developers to detect issues before their code reaches in front of your customers.
Let’s assume that the Platform team has its own Kubernetes Cluster to host all the platform-related components. Let’s also assume that the Production Environment is hosted in Cloud Provider A and it is also a Kubernetes Cluster. The company is using Cloud Provider B to host development environments for App Dev teams to experiment and build features. We are now in the presence of a multi-cloud and multi-cluster setup that requires maintenance, costs management, and it needs to be flexible enough to enable these different teams to do their work efficiently.
If the platform team wants to speed up and automate how software gets delivered to these environments or even how these environments are created and managed, for example, a new Development Environment is needed for a new project, the platform components will need to have the correct accounts and access to create and provision cloud resources on demand.

Every cloud provider gives us access to their APIs to create Cloud Resources, and to connect to those APIs, the platform cluster will need to have them accessible so the platform can create, manage and delete resources whenever needed in an automated fashion.
Things get interesting, at least from my perspective, when you start trying to define which tools and projects the platform will use to make our Application Development teams' life easier. Some of the main areas that the platform need to cover are:
- Continuous Integration: How will you build, test, and containerize your applications? Where are these tools going to run?
- Continuous Deployment: How will you deploy new versions of your applications when they are ready? Do you want to implement GitOps? Do you want to implement different release strategies (Blue/Green, Feature Flags, Canary Release, A/B testing)?
- Identity Management and credentials: who has access to what, and what are their permissions to see or create resources?
- Managing Environments and cloud providers integrations: where are things going to run? What level of isolation do you need between different teams and applications? Do you want to enable teams to request environments on-demand?
While there are several options for each of these topics, choosing from these options and staying up to date with the direction of each of these projects is a full-time job. Every day we can see new projects being added to the CNCF Landscape. It becomes the responsibility of the Platform team to understand this landscape and build the platform, so the tools being used are hidden away (when it makes sense) from App Dev teams to avoid them paying the toll of learning new tools.
The advantage of using Kubernetes as the base layer for managing our computing resources is that it provides a clean separation of concerns between infrastructure (computers, VMs and Cloud Providers) and their consumers, who can rely on the Kubernetes APIs to configure workloads, and in these cases the tools and components that will run on these clusters. By using the Kubernetes APIs as the base layer for building platforms, the platform team can focus on the tooling that has been built to do things in the Kubernetes way, that is, installing tools that will extend Kubernetes to solve different aspects of the platform. As mentioned before, by focusing on Kubernetes, we are in the realm of tools that can work across different Cloud Providers. As we will look in the following sections, this doesn’t mean that we cannot use Cloud Provider-specific services, quite the opposite, we can use any service we want, but we will do it in a Kubernetes-native way.
But as you can imagine, now we have multiple Kubernetes Clusters and the possibility of creating more clusters on-demand when teams need them. We also need to install tools inside to make the users of these cluster life easier. So now, the platform will not only be responsible for provisioning new Kubernetes Clusters but also for installing tools on them and configuring them for whatever the purpose of those clusters will be.
There are a bunch of projects that can help you to tackle some of these challenges that I see more and more people using for the same reasons that I’ve described here. Let’s look at Crossplane, a project that allows us to provision cloud resources across multiple Cloud Providers.
Crossplane to provision multi-cloud resources
When starting your Platform Building journey, you will find that Crossplane (https://crossplane.io) is heavily associated with the topics I've described here. With Crossplane, we can reuse the Kubernetes Resource model to provision and create resources on different Cloud Providers.
Crossplane was designed to enable its users to create Kubernetes Resources that will be mapped to cloud provider-specific services. As a Crossplane user, you can create a "Cluster" Resource and send it to the Kubernetes API (where Crossplane is installed). Crossplane will provision a Kubernetes Cluster in the configured provider (GKE, AKS, EKS, etc.). In the same way, if you need to create a Bucket or a PostgreSQL database, you create a Kubernetes "Database" resource, and Crossplane will be in charge of provisioning these resources for you.

The nice thing about Crossplane is that it reuses the Kubernetes reconciliation loop to keep these resources in sync. This means that if we have any configuration drift between the resource that the user created and the live configuration in the cloud provider, Crossplane will try to align those configurations again or report the drift. This is quite a significant change compared with other tools in the "Infrastructure as Code (IaC)" space, where the script you run to provision infrastructure just runs once, and there is no live drift detection.
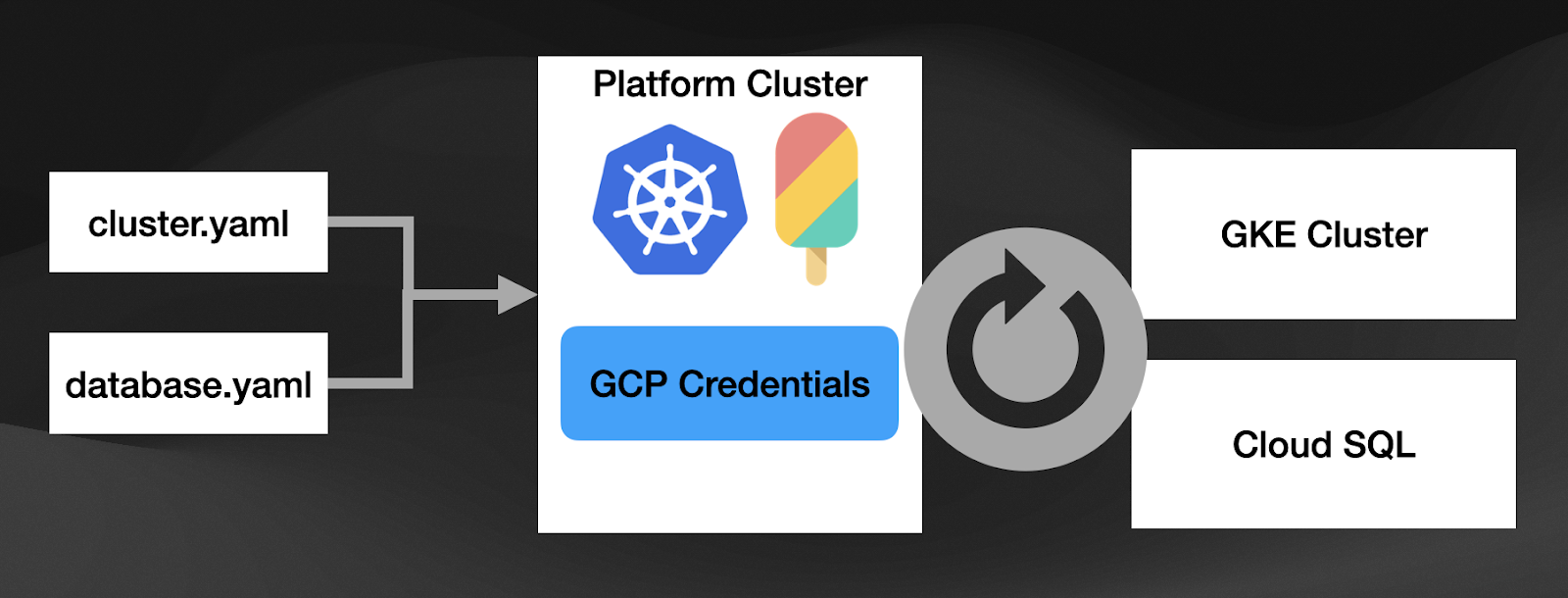
By adding Crossplane to the platform, we can now manage cloud resources across cloud providers by just defining Kubernetes Resources. I want to emphasize the fact that we are not only talking about creating dynamic Kubernetes Clusters here. You can create any resource available on the given Cloud Provider. And you might be wondering, but how about my internal Service that I also want to consume? Crossplane has got you covered. You can extend Crossplane to support any third-party service you can access using an API. Check out their Providers Development Guide.
But let’s be careful. Creating cloud resources costs money, and in particular, creating Kubernetes Clusters is expensive. Creating one Kubernetes Cluster each time that a development team needs an environment to test something might be too expensive to afford. In the next section, we will take a look at a project that can help us to keep costs down while at the same time it allows us to share cluster-wide tools across different isolated Kubernetes clusters.
Efficient use of resources without sacrifizing on isolation
I’ve seen firsthand how companies building internal platforms have started their journey by having a very large Kubernetes Cluster where they create different namespaces for their teams to work on. This reduces the number of resources needed per team but sacrifices isolation, as all cluster-wide resources will be shared. If your teams are building Kubernetes Controllers or if they depend on cluster-wide tools (on different versions, or they need to install their own tools inside the clusters), things get complicated. In other words, all your teams will be interacting with the same Kubernetes API server, which is where VCluster can help.
With VCluster you can create multiple Virtual Clusters inside a Kubernetes Cluster (called host cluster). VCluster works by creating a new Kubernetes API Server inside your Kubernetes Cluster. This isolates the API Server layer between the Host Cluster and the Virtual Cluster. The Host Cluster is still responsible for scheduling the workloads, but users can now interact with the Virtual Cluster API server.
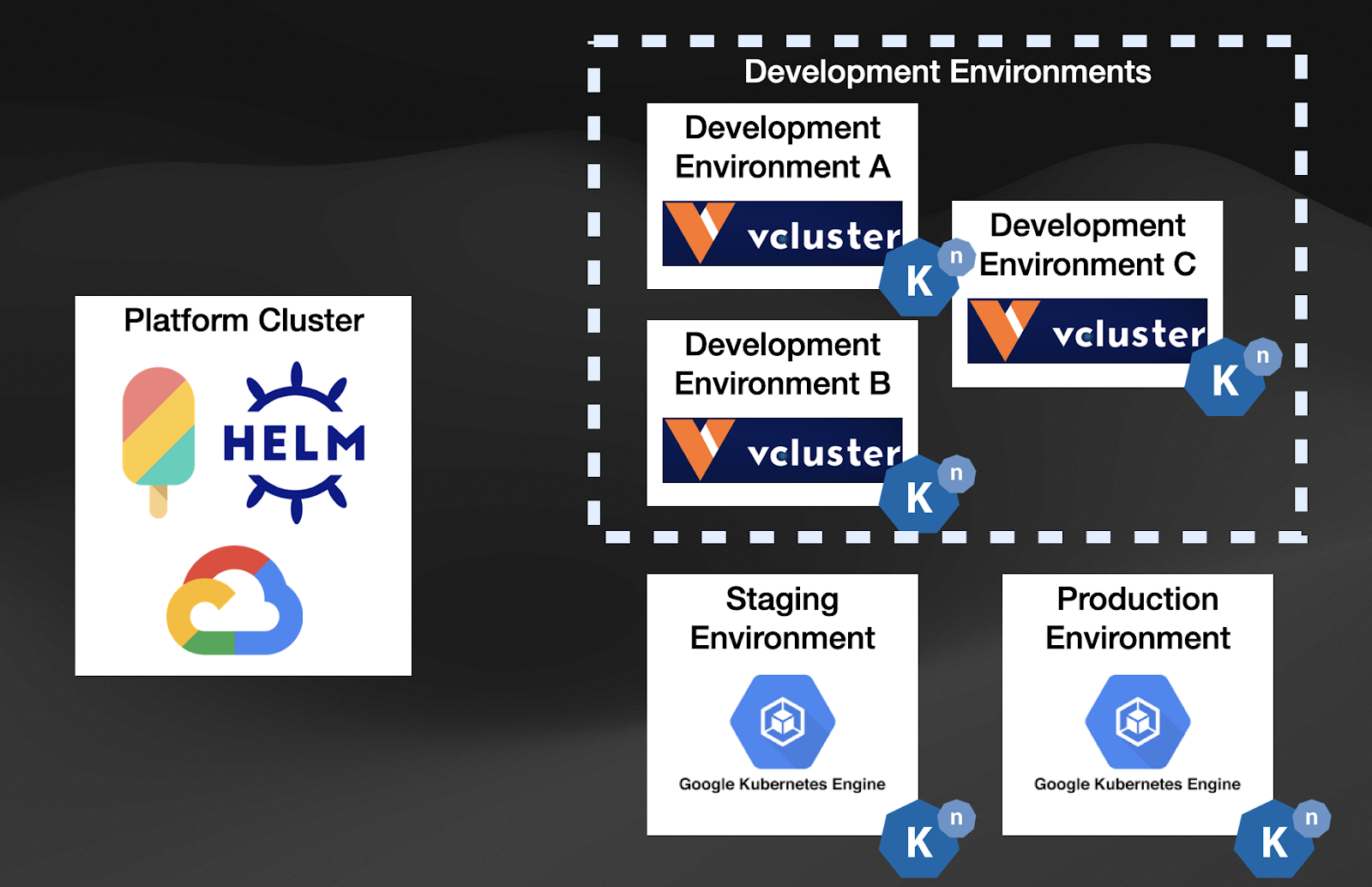
For our development environments, we can use VCluster as depicted in the following image:
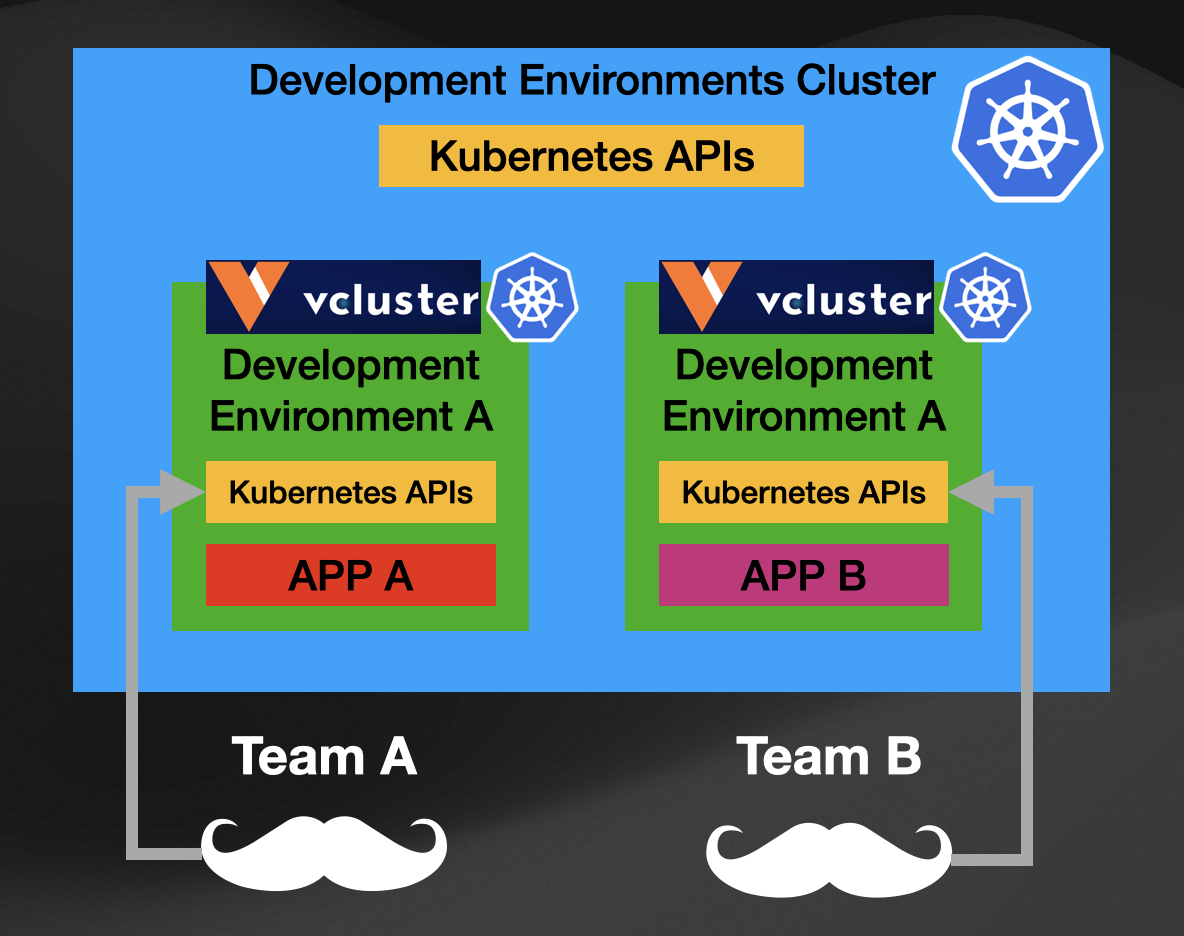
This approach (using VCluster) gives us isolation at the API level, allowing different teams to have their dedicated API Servers while the Host cluster is in charge of scheduling all the workloads.
Another fantastic thing about VCluster is how simple it is to create a new Virtual Cluster in our Host cluster. It took me a while to wrap my head around the fact that you don’t need to install anything in your host cluster to run VCluster. You can create a Virtual Cluster in any Kubernetes Cluster by installing a Helm chart. Yes, you read it correctly. You can create a new Virtual Cluster inside any Kubernetes cluster by running:
helm install my-cluster loft/vcluster
(before you need to add the Loft Helm chart repository with helm repo add loft https://charts.loft.sh and helm repo update to fetch the available charts)
Because I always find VCluster useful in conversations about what's better a namespace or a new cluster, I keep this table handy to explain why Vcluster is more than a good alternative, it might be what you are looking for:

If we put all the pieces (Crossplane, Helm, VCluster) together, we can now have a platform that can create dynamic Clusters!!
These Clusters can be Virtual or full-fledged Kubernetes Clusters running in different cloud providers. Using the Crossplane Helm Provider, we can install a Helm Chart instead of calling a Cloud Provider API. We have unified creating a cluster or installing a Helm chart using Kubernetes resources.
Let’s use Google Cloud Platform as an example:
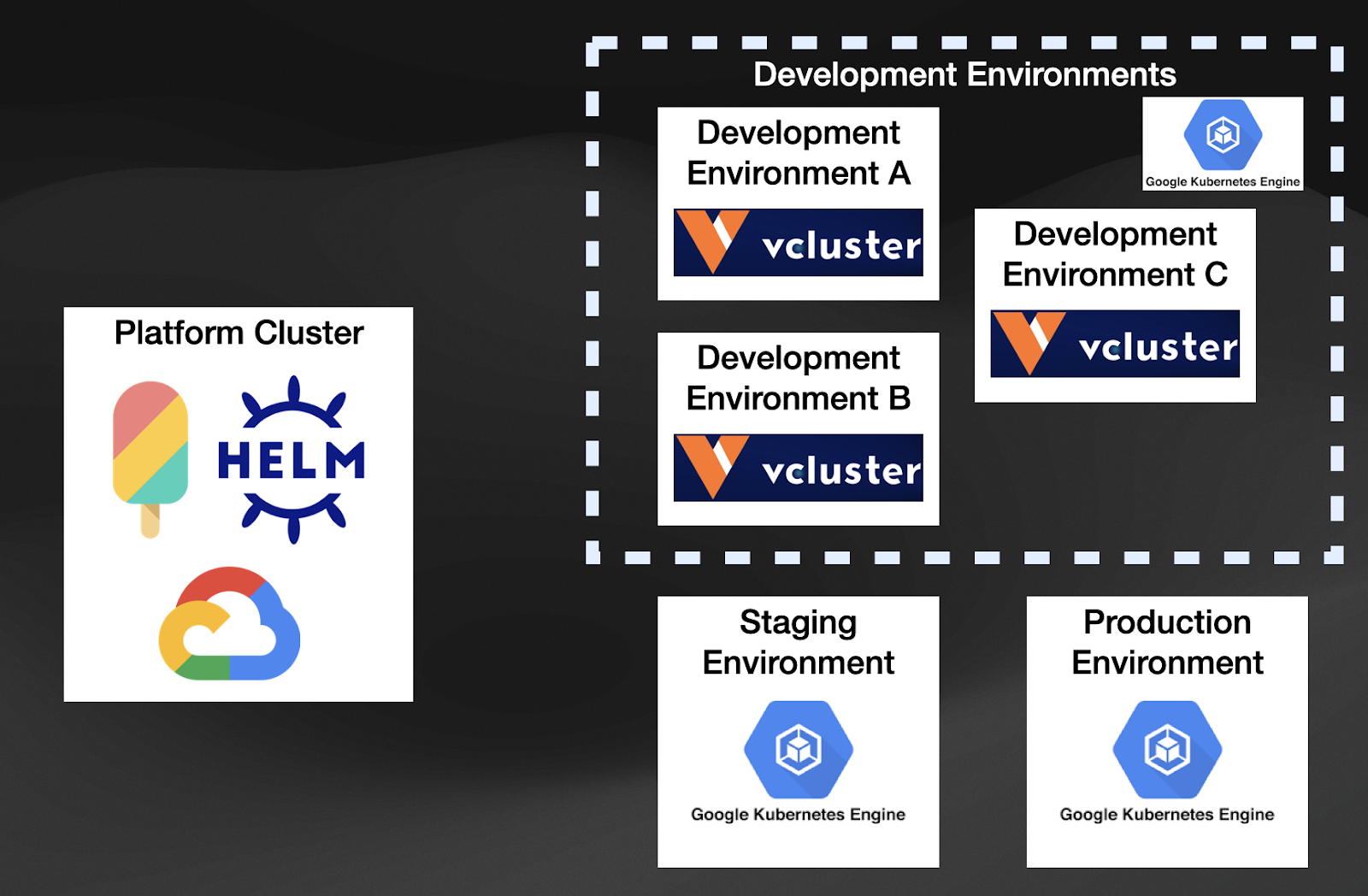
By combining these tools, your Kubernetes-based Platform will create both virtual and GKE Clusters using a declarative approach and allowing you to decide in which situations a full-blown Kubernetes makes sense and in which situations a Virtual Cluster will do.
If you are using Crossplane, you are managing these Clusters using the Kubernetes declarative approach and reusing the Kubernetes reconciliation loop, meaning that configurations drifts will be caught by Crossplane for each of these clusters. Crossplane becomes a control plane of control planes at this point, as you can quickly list which clusters are available and their status by interacting with the Platform APIs. In other words, if for every Kubernetes Cluster you create, you have a Cluster resource you can use kubectl get clusters to list all the clusters that the platform is managing.
But let’s be clear, just creating clusters will not cut it. Development environments will have specific requirements that bigger environments will not, like Staging and Production. Being able to have a cheaper alternatives for on-demand cluster creation like VCluster is excellent, but giving developers clusters is not even close to optimal. One difference that comes to mind when thinking about requirements that the platform should cover I think about how we want a fast developer loop and direct access to the cluster for development activities and how I would use a GitOps approach for environments such as Production and Staging.
In the next section, we cover the need to expand our Platform that can create Kubernetes clusters and install tools to enable teams to perform specific tasks and workflows.
Curating, Installing, and Managing tools across different Clusters
What tools do your developers need to run on the clusters they use to do their work? Platform engineers should work closely with Application Development teams to make sure that they have all the tools that they need, and if we are creating clusters for them to work, the platform should also install these tools to avoid pushing developers to install and maintain these tools in their environments.
Now, which tools should you use? Looking at the CNCF landscape is overwhelming and keeping up with what is happening in this vast ecosystem is quite hard. The tools you might want to use today might not be the ones you want to use six months from now. You need a flexible way to automate and glue different tools for different teams.
In this section, we will look at Knative Serving (you can do the same for any tool that you install once per cluster), a tool typically installed once per cluster, and it will monitor all the namespaces (you can fine-tune this) for Knative resources. Knative Serving extends Kubernetes with some interesting features that can simplify developer's life and enable them with advanced traffic mechanisms to implement different release strategies. Among other things, Knative Serving is usually associated with Serverless, as it comes with an auto-scaler that can downscale your applications to zero if they are receiving no traffic and automatically scale it up when new requests arrive.
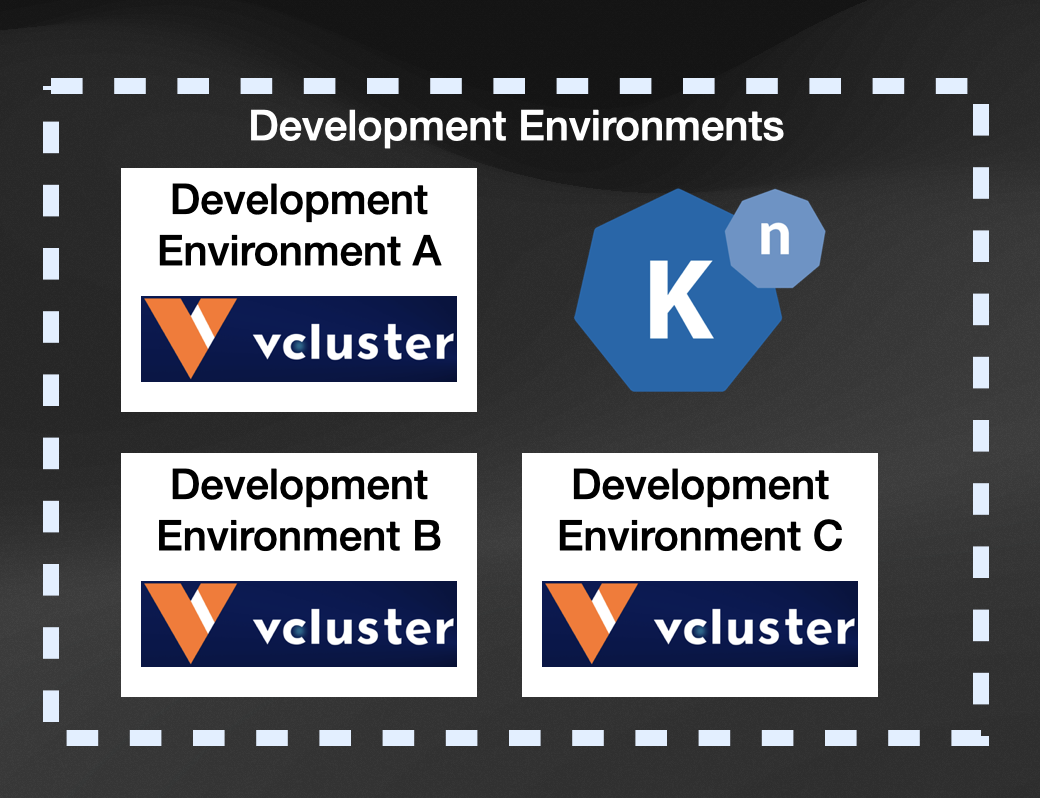
If you want to leverage Knative Serving features, maybe because you want to save on costs or use resources wisely, you will need to install Knative Serving in each environment. For our previous example, it would look like this:
Those are a lot of Knative Serving installations, maybe with different setups that you need to keep track of. Installing Knative Serving is one of those things that developers shouldn’t be doing as this can be easily automated by the platform, which can also define which version of Knative Serving should be used (blessed by the organization).
Notice that by installing Knative Serving in each cluster, we will need to pay for each of these installations (to run the Knative Serving components, which are pretty lean because Knative Serving is quite a mature project), and this can not only limit the number of environments that we can create due resources limits but also from a cost perspective.
Wouldn’t it be better to reuse these installations that work well across different namespaces but across different clusters? I think this question is becoming more and more relevant in the Kubernetes space as more and more platforms are being created and resources are wasted on running the same tools in different clusters. Let’s look at one tool that goes in this direction.
Welcome, VCluster plugins.
VCluster plugins help solve these inefficiencies by allowing the tools installed in the Host Cluster to be shared across all VClusters.
We just need to create our VClusters with the Knative Plugin enabled. The VCluster Knative plugin will be in charge of allowing users to create Knative resources inside their VClusters while syncing these resources up to the Host cluster to let the Knative Serving installation process the resources and then sync the results back inside the VCluster.
This provides more advanced functionality out-of-the-box for the virtual clusters and saves on the teams installing Knative Serving components in every Virtual Cluster they create.

Now teams connecting to different VClusters will have all the features from Knative Serving available to use, without having Knative installed inside that VCluster.
To finish this blog post, which became quite long, you can check a step-by-step tutorial that configures Crossplane along with the Crossplane Helm provider to create VClusters here.
Sum up
In this blog post, I wanted to cover a few common patterns I've seen companies implement while building their internal platforms based on Kubernetes. I wanted to share how projects like Crossplane, VCluster, and Knative Serving might be composed to provide this platform experience. We also covered the need for managing multiple clusters and cloud resources, as we want to use Cloud Provider-specific services. To achieve these, we focused on using and extending the Kubernetes APIs and Kubernetes Resource model. Finally, we looked at installing tools into these clusters, as providing application development teams plain Kubernetes Clusters might slow them down as they will need to choose which tools to install and maintain.
Remember that I am covering these topics in more depth in my upcoming book titled Continuous Delivery for Kubernetes, which is already available as MEAP on the manning website.
The following blog post of the series will be about the importance of the Platform API so Application Development teams can consume all this technology using a self-service approach without knowing every little detail.