
The evolution of Platforms (GenAI edition)

I’ve been thinking about a second edition of my book, Platform Engineering on Kubernetes, to cover all the progress I’ve seen over the last two years since its publication. Looking at industry trends and current applications of GenAI suggests that it may be too early to declare winners, but certain patterns are emerging. When patterns emerge, we tend to see quick-and-dirty solutions to demonstrate the path forward, and then a significant amount of engineering is required to turn those patterns into something that large organizations can adopt.
In this blog post, I will outline some ideas about the patterns I observe across various communities and vendors. Most of these tools, patterns, and approaches to using GenAI on platforms have been covered by my friend Viktor Farcic on his YouTube channel, which I strongly recommend you follow.
Here is my personal take on the matter.
A bit of context before we jump straight into the questions that we want to answer. We used and extended Kubernetes to build our platforms. We focused on APIs to simplify the consumption of platform services. We wrote a lot of glue to make this happen. Now that we have GenAI capabilities, teams consuming platform services want access to GenAI, platform engineers want to use GenAI to enhance their platforms, and there is a budget to adopt GenAI across the board.
The question is: how can we use GenAI to support platform initiatives while also providing GenAI capabilities to other teams that want to integrate these features into their applications?
Using GenAI for our platforms
With the rise of MCP, Agents, and prompt-based interactions, it makes sense to replace or extend our core platform APIs, which were built on top of Kubernetes APIs (REST endpoints), with an LLM-based prompt approach. This is not only for the sake of improving the experience, but also to gradually add capabilities emerging in the Gen AI space to our platforms.
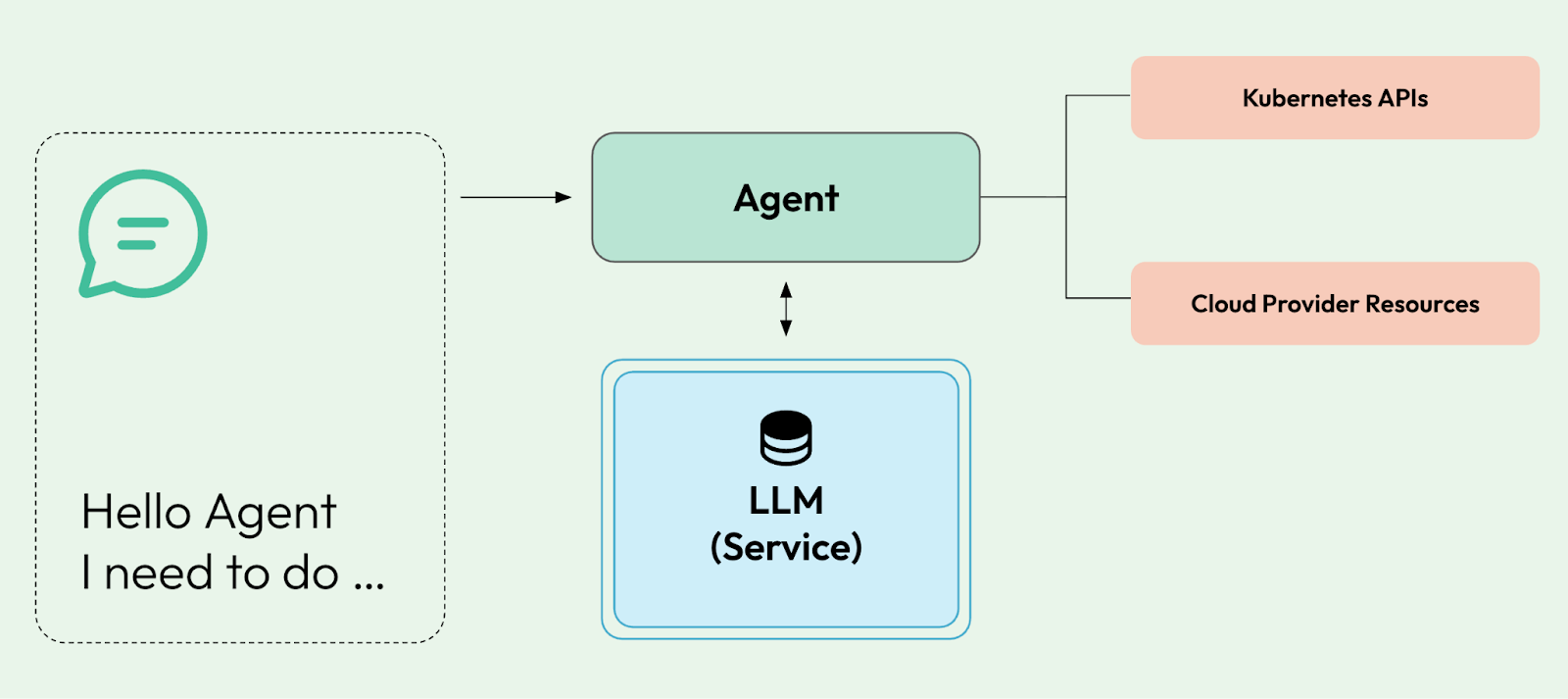
Some basic prompts that can be used to demonstrate the value of this approach can be:
- “I want to provision a new development environment for Team A, which uses NodeJS and MongoDB to build their applications.”
- “I need a new S3 bucket for application X which will store a huge number of PNG pictures, provide connection details after provision and connect the application to the bucket.”
- “Which services can I use to obtain the latest updates on Customer X from our organization’s services?”
- “Look at all the Issues on these 100 repositories, and for every issue created, try to provide a solution by sending a pull request with fixes.”
- “Monitor all my continuous integration pipelines. If something fails, try to troubleshoot the error and send a fix, and run again.”
First of all, this is not revolutionary; we have done this with our documents (Grammarly), with our code editors (Copilot, Cursor, etc), and in almost every industry, you will find services that are now frontfaced by what looks like an LLM.
Let’s assume we want to go this way. What would be the challenges that you will face on day one?
First and foremost, you need to decide not only where to start but also if you are going to use Public or Private LLMs. I will not go into the details, but at a high level, you will need to evaluate which option fits better for your organization, tomorrow and in the long run.
- Public LLMs
- Is the LLM Service just calling public LLMs like OpenAI, Anthropic, and Gemini? Well, this is going to cost you a lot of money, directly proportional to the use of your platform services. Can you afford this cost?
- The LLM will need to be enhanced with your organization's information to be valuable, in this case by providing access to your platform APIs and other services. Are you working in a startup where there are few regulations on where data goes or which services you can expose to LLMs?
- Private LLMs
- The real value of LLMs for organizations is having a custom set of models to perform very specific tasks tailored to the organization's context. While a fair amount of use cases can be covered with generic models, if you want answers from your prompts that take only your organization’s knowledge into account, you need to train your own LLMs. This is not only costly, but laborious and requires a lot of expertise. Guess what, hiring people to do this is hard, and these experts are in high demand.
- Whether you train or not, you still need to run your models. If your organization is highly regulated and you cannot interact with public services, you have no other option but to host your LLMs yourself.
No matter whether you decide to go with public LLM services (get your wallet ready) or if you want to host your LLMs on-prem, there are a few projects that you should check out:
- vLLM: full-on solution to manage, host, and route traffic to your LLMs that run on Kubernetes. This project helps you schedule LLM workloads that require GPUs to run at a usable speed. People from Google, Red Hat, and other companies are collaborating on this project.
- AI Proxies
- Envoy AI Gateway (token-aware router): No matter which LLM provider you are using, having a proxy layer between your consumers and the LLM service allows you to set up quotas, filters, and policies for cost control or transformations to reduce the burden on consumers to know which LLM service to consume.
- Dapr Conversation API: a higher-level abstraction to enable applications/agents to talk to LLMs without the need for a specific provider SDK to be included inside your app/agents.
System Integrations, we know how to do this
Going back to the challenges, I wanted to touch on the system integration issues teams will face when implementing such an extension to the existing platform APIs.
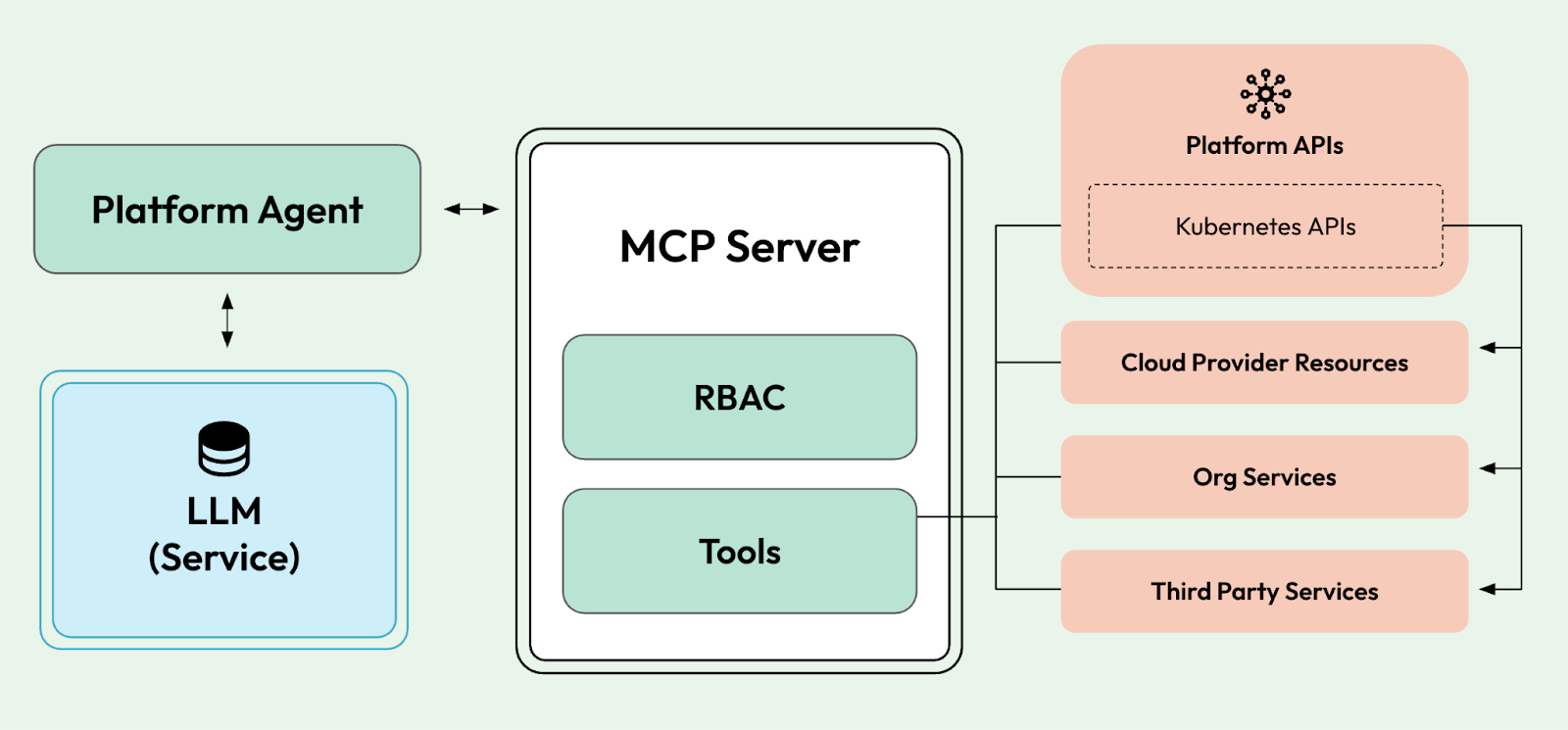
To make the LLM do more than just reply to text, we need to connect it to services so it can actually do something useful, such as automating platform tasks. To do this, the industry has settled on using the MCP protocol to connect LLMs to other services, so that, as part of user interactions with the LLM, the LLM can trigger actions on external systems.
Besides the network complexities required to secure and make these interactions resilient, MCP serves as the glue between a text-based world and a very service-oriented world, where APIs are the default way for developers and machines to interact with services. Here, I want to reflect on how APIs have served as contracts to define system-to-system and human-to-system interactions, with well-defined inputs and outputs and non-functional requirements. This makes the MCP protocol the perfect place to bridge the purely unstructured world of prompts to the heavily structured world of APIs.
In the world of MCPs, APIs are considered tools, and tools have their own contracts, so a translation layer is still required between the APIs in our organizations and the tools in the context of MCPs. This forced translation has led to an industry-wide push to advertise that every project, product, and service includes a built-in MCP server.
For example:
- Kubernetes MCP Server
- Argo CD MCP Server
- Crossplane MCP Server
- Awesome MCP severs list proves the point
What this means for an organization trying to enable its internal systems to be accessed by LLMs is some work to figure out how to call these services using the MCP protocol. Tools in this space are popping up to help companies create MCP tools from their existing service APIs.
An important change is that, as shown in the previous diagram, the services that were previously handled and hidden behind the Platform API can now be accessed directly by the LLM. In some way, this means that as platform builders, we will be in charge of defining how low-level we want our LLMs to be able to perform actions. Do we want the LLM to have access only to platform APIs, or to all the tools used to build the platform?
So at the end of the day, there is no centralized MCP server with a huge list of tools for an LLM to access all the services, but it follows a more distributed approach:
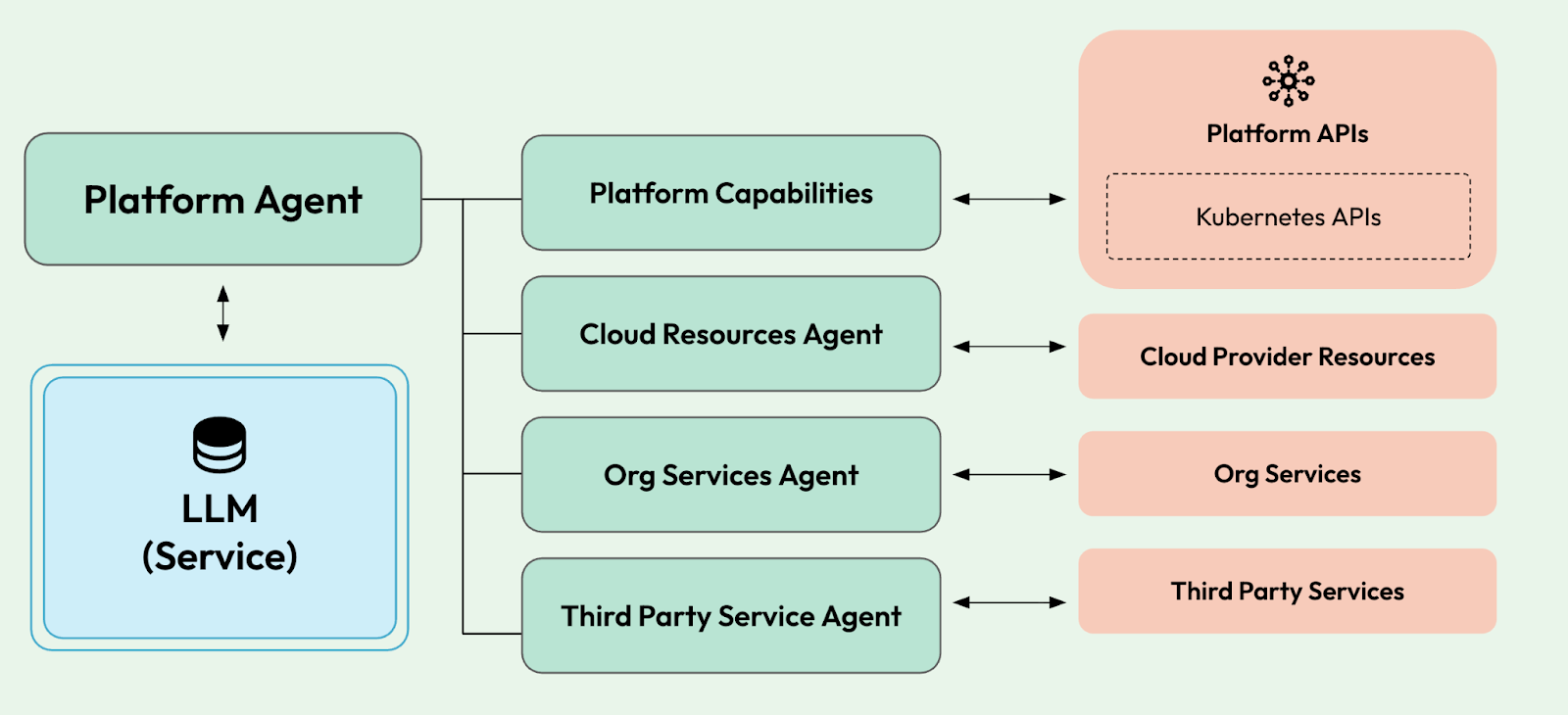
If we follow this approach, we can control, using RBAC, which tools each MCP server exposes and provides to the LLM.
If we focus on our platforms, it is difficult not to look into Kagent, a project created by Solo.io and donated to CNCF, which has attracted attention in this space, as it provides out-of-the-box agents that work with the Kubernetes APIs and other, more specific Kubernetes-based projects, such as Istio, Cilium, Helm, and Argo Rollouts.
Check kmcp and the agents registry announced last week at KubeCon
NOTE: You will find several reports about LLMs hallucinating and using way too many tokens if you give them a large number of tools [1], [2], [3]. This not only raises a scalability issue but also questions the need to craft custom solutions to give LLMs what they need at the right time.
The problem with this approach is that the LLMs have very limited tools for performing actions. This means that tools related to interacting with the Kubernetes APIs will require the LLM to know about Deployments, Services, StatefulSets; hence, achieving higher-level automations such as “connect my application to a database” could be extremely hard to achieve, as the Kubernetes APIs do not expose higher-level concepts such as applications and databases.
This takes us to the next iteration of this pattern. Let’s enhance our LLMs with concepts and their relationships.
Softening the contracts
What does a “Customer” mean? What does “Application” mean? What does “deploy to production” mean?
If you ask a public LLM about these concepts, you will get very generic answers, mostly coming from the training data (the internet), which will not make much sense for your organization.
One way to solve this problem is to use vector embeddings to represent concepts and their relationships (links), so that LLMs, when asked about Customers or Applications, understand exactly what this means for your organization.
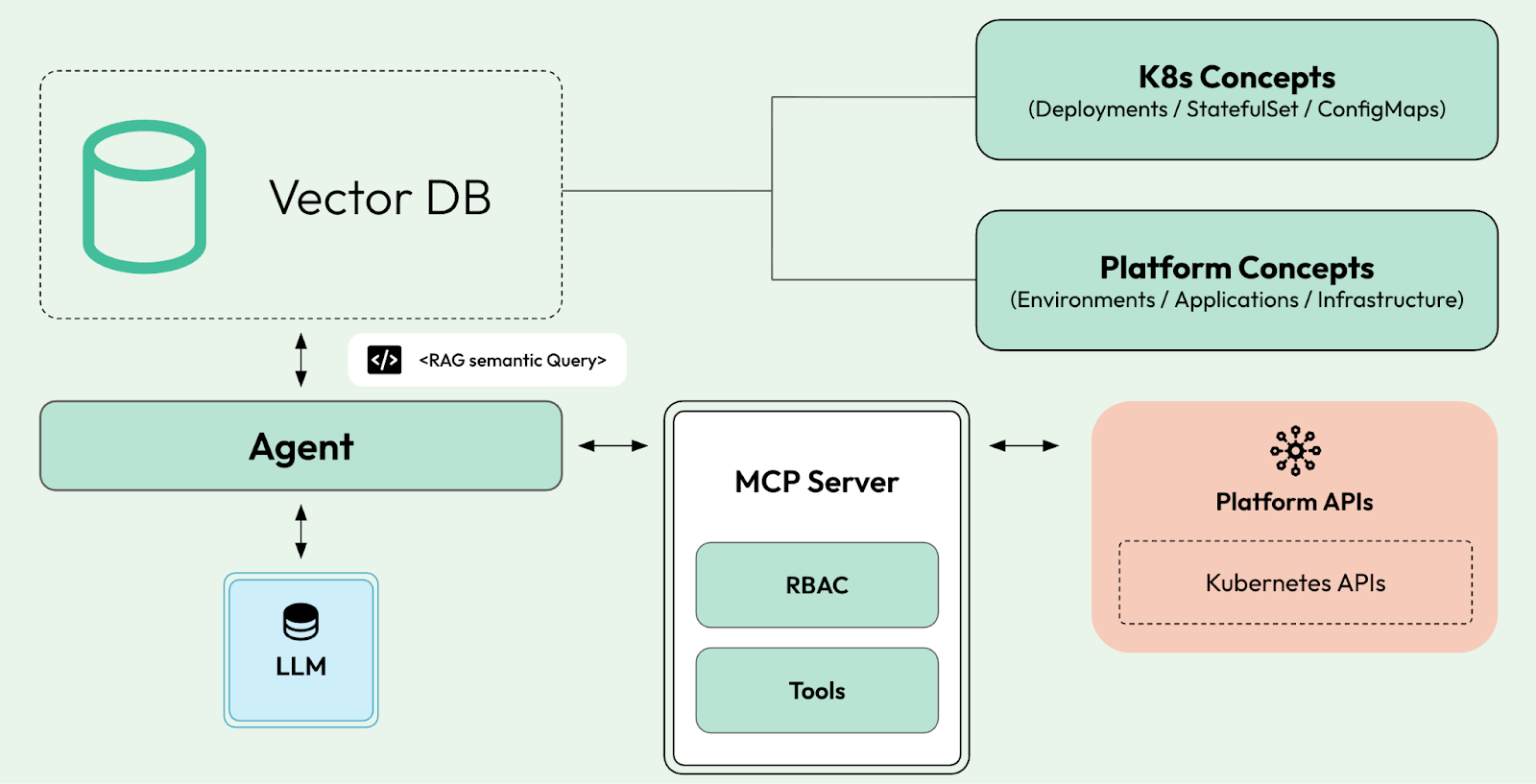
With vector embeddings, we can ingest concepts and create relationships between these concepts, so when we create a fuzzy prompt to LLMs, we can use RAG(Retrieval augmented generation) semantic searches to supplement the LLM's knowledge base.
By doing this, when prompting, we can be less specific about implementation details and focus more on the prompt's desired outcome.
To give a more specific example, let’s imagine a team has been developing a new application that they want to deploy into a given environment. This new application depends on a relational database that hasn’t been provisioned yet.
A prompt to the platform can look like this:
“Deploy the application hosted in the following GitHub repository Y to environment X, but before make sure that a new database is provisioned for the application to use.”
To determine what needs to be done and where, the LLM can run a RAG search against the vector database to identify which tools from the Platform and Kubernetes APIs can be used to make that happen.
By looking at the platform APIs, it can retrieve the given environment, where a new application can be deployed. Also, by looking at the platform APIs, the LLM can understand how to build the application source code and create deployment manifests. Depending on whether the platform provides APIs to provision databases, a RAG search can identify which databases are available for applications to use, and applications can then directly use the available cloud provider APIs to create a new instance. Finally, it can use the Kubernetes APIs to bind the database to the application after deployment.
We have configured our setup to handle higher-level concepts and perform lower-level operations against the Kubernetes APIs when needed.
Using RAG to filter which tools LLMs can use to perform a given task is a pattern that is maturing quite quickly; hence, new tools to help teams implement these interactions are popping up in the market. The rise of tools like PG Vector (PostgreSQL vector database) are in high demand.
So the question is now: how does it know which database to use for a given application? How does it know which region this database needs to be provisioned in? How does it know how long this database should store data?
Companies' guidelines, best practices, and policies
Providing our LLMs with access to Cloud Provider APIs, Kubernetes APIs, and third-party service APIs sounds really cool, but brace yourself: you are opening the door to pure chaos. As with people, when having access to all these resources, it is a good practice to have strict rules and policies on where resources are created, quotas, and which credit card is used to pay for them.
LLMs are no different; hence, providing access to our platform APIs should encode some of these policies, but we want to enable low-level interactions when needed. This means that we will need to teach our LLMs to also learn about our organization's guidelines, policies, and best practices.
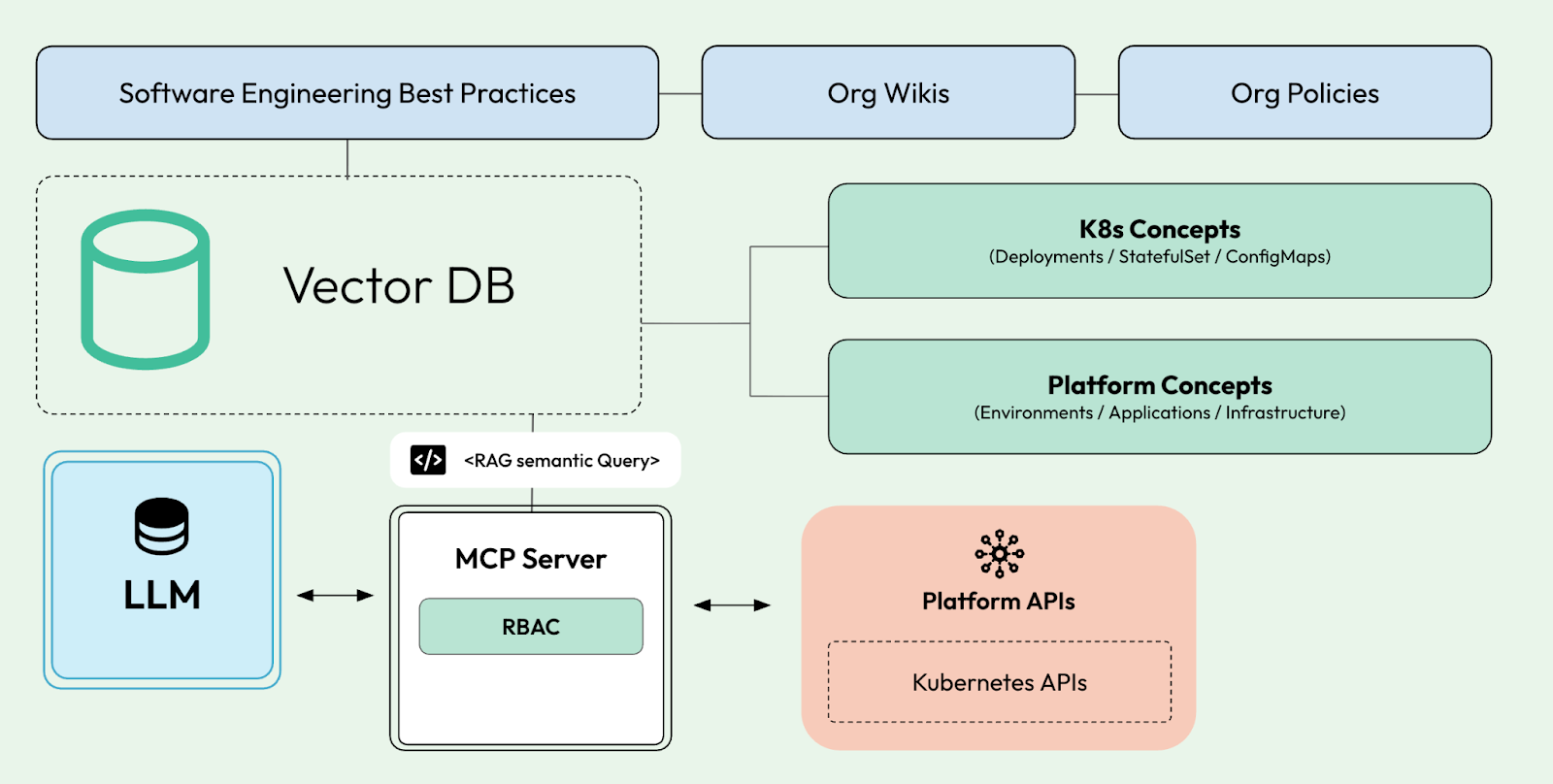
While we can provide LLMs with knowledge about company guidelines, best practices, and policies, it is recommended to have one last line of defence. Using policy engines such as Kyverno as part of our platform will let the LLM decide what to do, but it will not allow it to proceed with operations that do not adhere to company policies.
On this note, you can find the folks from Nirmata mixing kagent and Kyverno in this video. Where they show how the Kyverno MCP server can be used by Agents to create, check, validate and enforce policies.
If we stop for a second to recap what we have achieved so far, we can see that we have enabled LLMs with a bunch of new tools to perform actions on our behalf, we have softened our contracts by using vector embeddings and RAG semantic queries for the LLMs to be able to bridge the gap between fuzzy prompts and structured APIs, and we have provided the LLMs with organization knowledge to constrain its suggestions and actions to follow what the organizaiton is already doing in other projects. Still, the more tools and concepts we provide to the LLMs, the more coordination these interactions will require to be useful. Going step-by-step with an agent-assisting platform engineering team to achieve their goals requires more advanced state and resource management; we need workflows.
Workflows & Context Management
LLMs are stateless, have limited context sizes, and can get confused if we provide too many tools. This means that if we have a long chain of tasks to perform, we need more complex coordination and a state machine to track all the interactions.
It is also important to consider interaction patterns with platform builders and teams that consume platform services. Going back to the example that we used before:
“Deploy the application hosted in the following GitHub repository Y to environment X, but before make sure that a new database is provisioned for the application to use.”
Instead of expecting all this to be resolved in the background, our platform front-facing LLM-enabled service should guide the user to accomplish the goal by performing a well-defined set of interactions that provide advice on every option along the way.
What do we need to implement this to make sure that:
- We have a way to define concrete and consistent steps that our agents will execute
- Make sure we have a way to control what is set into the context for the LLM to have the right information to perform the task at a given point in time
- Keep track of where the agent is at all times, so we can report back to the user, but also make sure that if something goes wrong, we can resume from where the agent left off
Guess what, Workflow and durable execution runtimes were created to solve these challenges. Imagine the following workflow that the agent can call to perform a set of actions in a sequence:
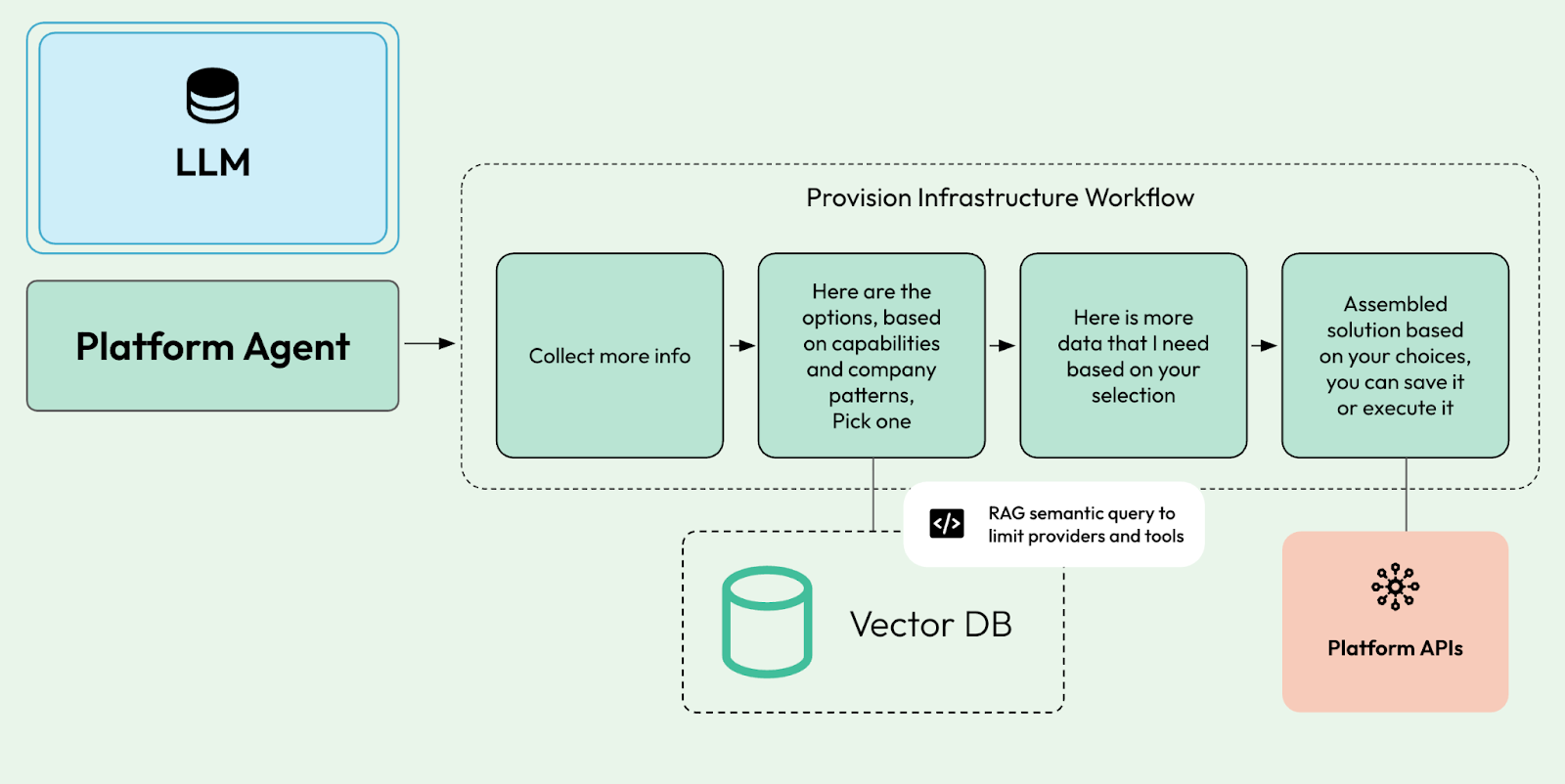
At each step, we can retrieve information from the vector database to refine the task at hand, check with other systems to gather more information, and perform and validate actions.
With workflows, we can break complex tasks into more manageable steps that can also be used to reduce “context pollution” and tool overload.
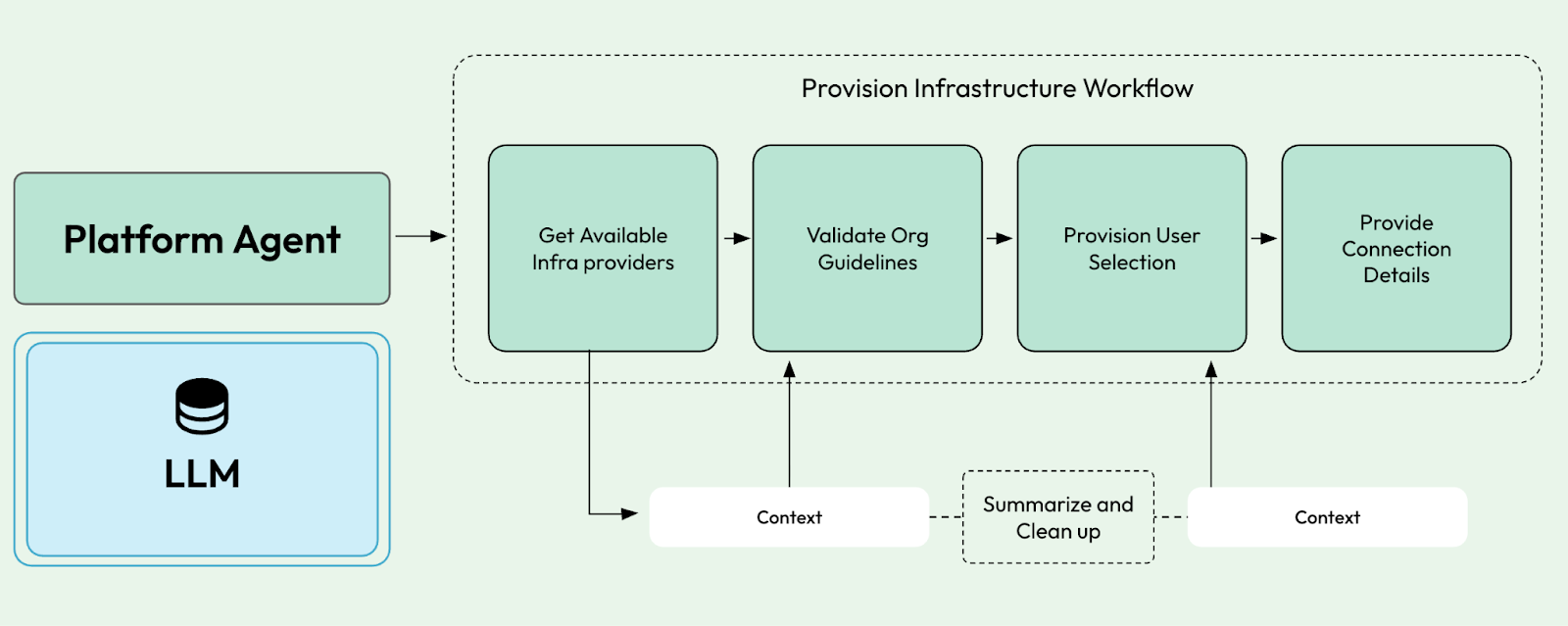
Using workflows, we can mix and match, letting our agents decide when to perform a chain of well-known tasks or execute separate actions based on user prompts.
The advantages of using durable execution frameworks to run our workflows include visibility into the agent state (since LLMs are stateless, the agent is responsible for maintaining state and progress for its operations) and durability. Durability is important because each interaction between our agents and LLMs costs money.
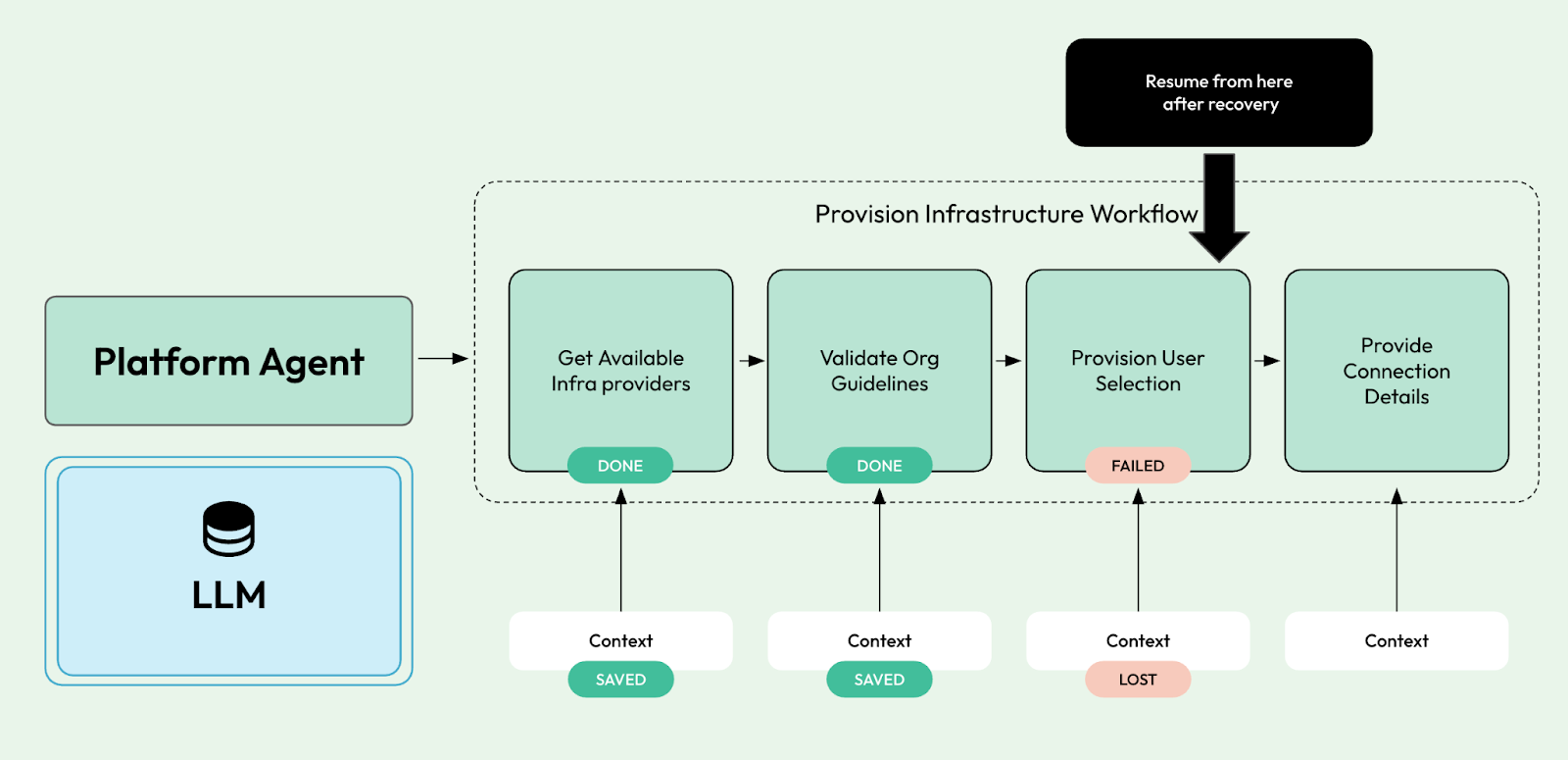
In a world where everything becomes a Tool exposed using the MCP protocol, workflows are here to provide a middle ground where the LLM can choose which workflow to execute in a non-deterministic fashion, but when a workflow is started, a set of steps will be performed in sequence to completion.
Workflows-as-tools is already a term that is being used to bridge this gap between the fully non-deterministic agents and agents that can choose to execute a set of tasks that require special and deterministic coordination across multiple steps.
If you are considering building these kinds of agents or applications, you should check out Dapr Workflows, which provides a Workflow-as-Code alternative for building durable agents.
If you are working with Python already, Dapr Agents provides a more opinionated programming model to create durable agents that implement all these mechanisms out of the box.
Other tools and specs that I am keeping an eye on are:
- Compass for context tracking and clean up
- Recursive RLMs instead of LLMs
- vLLM semantic router for tool selection, providing
Sum up
Bringing GenAI closer to our Kubernetes-based platforms requires platform engineers to wire a new array of services and tools. When I look at the patterns described earlier, I don’t see anything beyond new constraints and integration challenges.
As part of bringing GenAI services closer, our platform surface will expand we will need to manage more infrastructure, tokens, and services. Expertise in RAG frameworks and vector databases will become essential for platform teams in the near future.
As we have covered what it means to bring GenAI to our platforms, enabling development teams with GenAI services or features becomes a natural extension to the same problem. In the same way that our Kubernetes-based platforms became an enabler for teams that needed a Kubernetes-based environment for their applications, platform teams that manage to integrate GenAI services will be able to understand the nitty-gritty details of how these services are consumed, providing them as a service to others.