
DevEx in the age of AI
I’ve been trying to write about this topic for a while, but the feeling that we already have too much content, much of which can be auto-generated, has been slowing me down lately. The question “so why bother?” still resonates.
When we started with Thomas Vitale on the project to write about Developer Experience for Kubernetes, we knew we would need to cover AI, LLMs, and other strange tools that would pop up as we wrote the book. This is the rule in our industry: nothing stays the same for a year.
Writing a book is always messy, and ideas tend to change a lot. To define core and fundamental topics that continue to affect developers working with cloud-native technologies, we focused on tools and practices that will remain a must for engineering teams moving forward.
But it is true: the industry has massively changed, both in terms of speed and the kinds of tools popping up. In the last year, we have seen new protocols, libraries, CLIs, and IDEs popping up like crazy and also changing at unprecedented speed. A tool you learn today may not be around tomorrow, and developers need to adapt.
In this blog post, I wanted to cover my biased journey to the land of coding agents and, instead of comparing the features of the different tools available in the market, focus on the fundamentals.
Stepping back from the day-to-day of using code-generation tools might help us seize opportunities and avoid mistakes that push us several steps backward. Based on my experience writing the Platform Engineering on Kubernetes book, I can assure you that whenever you talk about Developer Experience, you will, in some way or another, involve Platform Teams, so expect to see a lot of parallelism in this blog post. Whenever you need to deal with constant change and new tools, you can use all the things we learned when building platforms.
Before we start, a bit of a disclaimer: this blog post is not about building domain-specific or business agents. There are tons of frameworks popping up to create business agents, rather than code-generating agents. I’ve been following agentic frameworks for business purposes, and I am sure I'll write about them in a separate article.
All the examples from the tools described in this blog post can be found in the following GitHub repository: https://github.com/salaboy/kubecon-eu-2026
Coding, before agents
The developers' inner loop is a term that has been used for more than 20 years to describe the tasks that developers perform in a loop to get stuff done (that is, creating new features or fixing bugs). These loops are well understood and learn by heart by developers (no matter which company they work for).
code → build → test → debug → repeat
These loops are time-consuming, as coding requires understanding what needs to be done and where the changes need to happen. Building is usually automated, but unless you work for a company with only one application, testing tends to be complex. If you are like me, when writing a feature or fixing a bug, you can plan for a couple of happy paths and some edge cases, but for the most complex scenarios, debugging is required.
Each of these activities takes time, and no matter which company you are working for, there are a couple of things that you, as a developer, need to master to be efficient while going through these loops several times a day:
- Tech stack-specific libraries and tools
- Company-specific (homegrown) frameworks and tools
- Company culture, practices, processes (where the source code repositories are, what my team can change and what we can’t, and already discussed and defined architectural patterns)
Moving companies means you, as a developer, will need to relearn most of this. While you can leverage your knowledge about a given framework or a programming language, getting accustomed to the company-specific procedures is just a painful process.
Over time, programming practices like TDD (Test-driven development) and BDD (behavior-driven development) have been adopted by different organizations, but I wouldn’t dare to call them standards. The larger the organization is, the more complex the code they need to produce, so more complex practices are required. Spec-driven development was also a thing back in the 2000s, with UML (Unified Modeling Language) as the de facto standard for defining software specs.
While these loops are focused on a single developer, it is important to add additional context on how they work.
requirements → inner-loops → code(PR) → outer-loops
These inner-loops main mission is to transform requirements (what needs to be done) into code. In my opinion, the value of a developer performing an inner loop lies in learning to translate ideas into code and mastering the technical skills required to do so. When I am performing manual inner loops, I am learning how complex systems work. It is totally valid to argue that after you have done several features and fixed bugs, there is not much more to learn, the learning process decreases over time, and tasks become repetitive and mundane.
After having produced code to implement a set of requirements, this code needs to be shared (usually in the shape of a pull request, if we are using Git), so the code can be reviewed, tested, and validated against other components, and finally merged into the main code base of our applications.
Note: other practices, like pair programming during inner loops, have proven very beneficial, boosting productivity and knowledge transfer, but, once again, these practices are in no way industry standards.
The outer-loop is when collaboration happens. As part of reviewing a pull request, I need to use the same mental model the creator used to produce the code and to apply my assumptions and understanding of the application to validate their changes. Once again, while reviewing pull requests, I do learn quite a bit, not only about the code changes, but also about the architecture of the application and how it will run in a production environment.
Coding, with agents
Let’s now talk about coding agents.
I will use Anthropic’s Claude Code because I’ve been following and using it more often than other tools. I do think that Claude Code is representative of the evolution of these coding agent tools.
Claude Code is designed to replace all activities in the inner loop by transforming prompts into code, running tests, debugging, and troubleshooting until the requirements are implemented. Someone can argue that you can give Claude code the credentials to also automate deployments and control the full software delivery cycle, but I haven’t seen this implemented at scale yet. If we focus only on the inner loop, it is important to say that Claude Code is a generic agent. Using an LLM model, an agent harness has been built to help replace the inner-loop tasks that developers used to perform. These coding-agent harnesses include all the workflows, tool calling, memory, guardrails, and understanding how to use local tools to get stuff done.
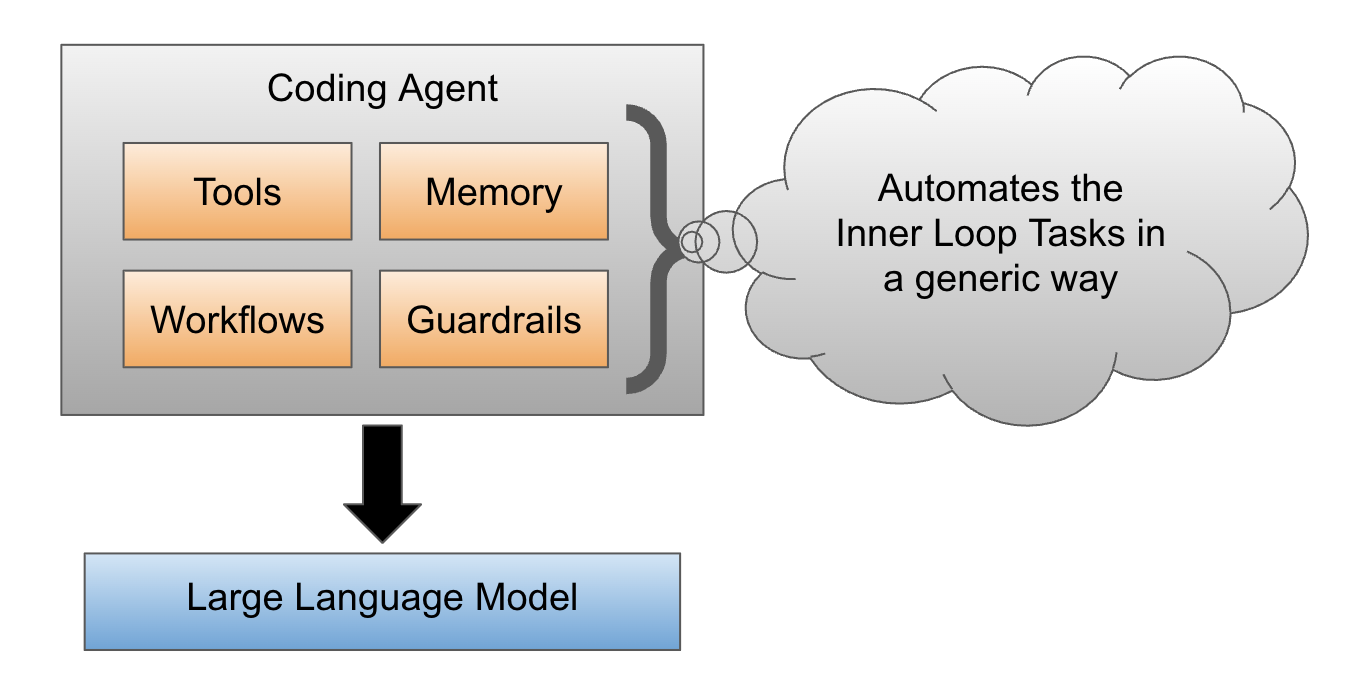
Claude Code is a CLI (terminal application), an IDE plugin, or even a web app that allows developers to write their prompts to generate code. I’ve tried IDE plugins, but the CLI still works best.
To see the level of change in these tools, Claude Code consistently requires you to upgrade its version every day, which forces users to fetch a 200~MB (monolithic) binary containing improvements (we all assume). How many large companies can accept this speed of change in a secure and reliable way?

I want to reemphasize that Claude Code is a generic tool that uses different LLMs depending on the task that we want to perform. On the CLI, you, as the user, can select which model to use, which prompts you to decide whether you are after a complex task or something that can be considered a “quick answer”.
Because it is a generic tool, there are things that can be done, but defeat the purpose in my opinion. For example, if you create an empty directory, run the Claude CLI inside that and prompt:
“Create a Spring Boot application that implements some REST endpoints to manage Customers”
It will do as told, but there are a few caveats. First, it doesn’t know which versions of the frameworks to use, so it will choose a popular version; it doesn’t understand your domain models, so the concept of a Customer will be defined as part of a generic code-generation process.
While this works, Claude is much more effective when context and guidance are provided. Unfortunately, context and guidance are what make Senior Developers, senior.
I know this sounds obvious, but after using Claude for quite a while, I’ve noticed a boost in my productivity when I scope the problem at hand. This is not only for Claude to be more efficient, but it also helps me think and learn while I let Claude generate code that it can test and debug until it does what I need. So here are a few practical examples:
- Instead of asking Claude to create a project, I create it and define the core versions of the frameworks I want to use for the application. I need to make sure that Claude does not change these versions or add new libraries without my approval. This can be done in different ways, such as using skills and guideline files, such as Claude.md (Agents.md) . There is a parallelism with creating templates in Backstage for developers to use when starting a project.
- Designing domain objects and APIs for a given problem is such a fundamental part of the process that providing that context helps, since the code generation is bound to those APIs. Having a centralized database of datatypes and structures that must be used by code generation would make sense for a large enterprise scenario where data standardization is a must, think about healthcare scenarios.
- Architectural decisions are always implicit in a senior developer's mind when deciding on how to implement features. For coding agents, providing architectural guidelines completely changes the output. Failing to provide sufficient architectural guidance (only needed when building distributed applications) allows the model to make changes beyond what is already defined in the architecture. Think about how to provide coding agents with ADRs (Architectural Decision Records) related to the task at hand. Tools to find these ADRs and categorize them so coding agents can fetch the relevant ones sounds like a sensitive thing to explore.
- Using TDD is very rewarding, as you focus on writing tests first, covering happy paths and some edge cases, and then the code follows. If the APIs are already defined, then multiple features can be implemented in quick iterations. For me, this is where I’ve refocused my learning process. I force myself to identify which tests I need to pass so I can spend time reviewing the generated code.
- How we define what a development environment is (the tools needed to run all the tasks in the inner loop) is critical for the coding agent to perform these tasks. Currently, coding agents request many permissions, and if you mistakenly grant them too much freedom, unexpected things can happen. Sandboxes and control over which tools the coding agent can use are critical to making the whole process more reliable.
- It goes without saying, but if you don’t use version control, tracking iterative progress becomes really hard. There is a fine line between understanding what the coding agent is doing and complete chaos. If you cannot review a whole changeset at once, it is hard to keep up with the changes, and more importantly, it is hard to revert to a previous state.
Interestingly enough, coding agents are now introducing what is known as “planning mode”, where you can ask the coding-agent to question you about these topics, so it can have enough context to produce what is expected.
At this point, I tend to say these practices apply to all coding agents, but there is a problem...
Who owns the experience?
If I am upgrading a monolith 200~MB CLI (claude-code) every 8 hours as a user (or organization), I don't have any control over the experience that I have with these coding agents.
As we experienced with cloud providers, organizations will want to craft their own custom experiences, moving away from generic workflows and guardrails that are not sufficient for their more specific scenarios. In the cloud space, this led to Kubernetes becoming the building block for companies to build their custom platforms. I see something similar in the coding agent space, tools that provide the basic building blocks so teams can craft and share their own experiences.
In that space, I see tools like Docker Agents showing some very interesting ideas enabling teams to own and share custom agents definitions.

Using a declarative approach (YAML) with Docker Agents we can define a team of agents, where each agent can use a different model to perform tasks and specify which tools are available for the agent.
You can run this team of agents now using docker agent run agents.yaml
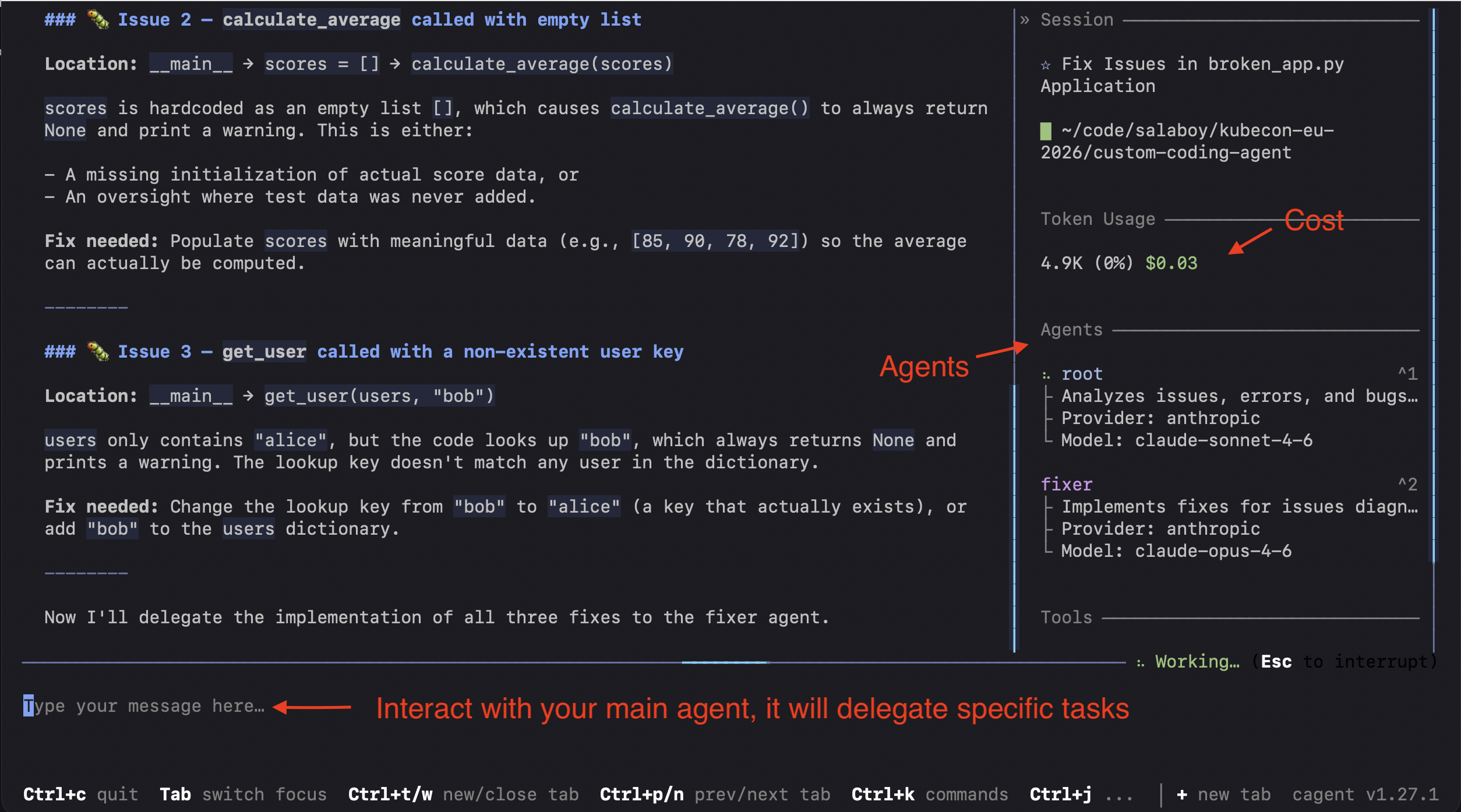
This experience is available as experimental if you have Docker Desktop installed on your laptop. And I know, at first I was like, ok .. declarative team of agents, definitions, custom UI, cost control, and tools restrictions, cool. But what really caught my attention is that teams can share these definitions as OCI images.
By running docker agent share push ./agents.yaml salaboy/my-agent you can publish your agent definition to Docker Hub https://hub.docker.com/r/salaboy/my-agent . Now, if you have a team of developers all using coding agents, you can share these teams of agents with all the teammates and control these agent versions with all the tools that we already use for our application containers.
Are Docker Agents the solution to all your problems? Definitely not, but I do expect more tools following up on these lines.
Who controls the experience?
Well, if we can share agents' definitions as OCI images, we should be able to also define with a high degree of control what these coding agents can see and do, but that is quite a hard task if the coding agent binary is running on a host machine (workstation).
Just to show an example, if you have the following directory structure:

And you move the project/ directory and start a claude code session:
You can prompt the agent to go, read and print the secrets in the ../secrets/ directory. The agent will ask for permission because it is outside of the scope of the project/ directory where the session was started.
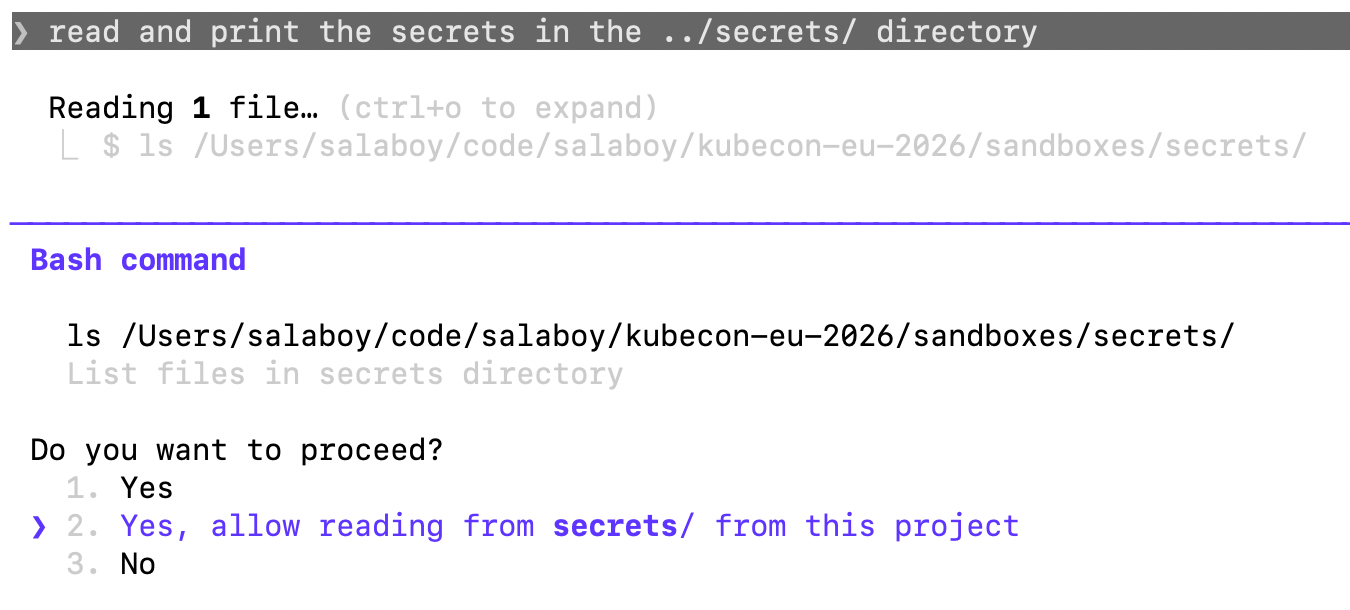
This is not a problem per se, but it becomes a problem when the developer in charge has answered hundreds of similar questions. Wouldn't it be nice to let the agent run in YOLO mode?
That is the problem Docker Sandboxes are to solve. With Sandboxes, you can control what a coding agent can see and do by running each session inside a microVM.
With a single command, I can start a Claude code session inside a sandbox and I can "mount" whatever directories I want the agent to have access to:
docker sandbox run --name my-demo-sandbox claude ./project
Mount is not the right word here, because sandboxes do file syncing between the microVM and the host machine. This also allows setting up directories of files in read-only mode, which makes the agent able to access the files but never (accidentally) change them.
Now, your coding agent (in this case, Claude code) can only see the contents of the projects directory and try to perform the same prompt as before to read the secrets, it will fail as the microVM doesn't have access to those files:
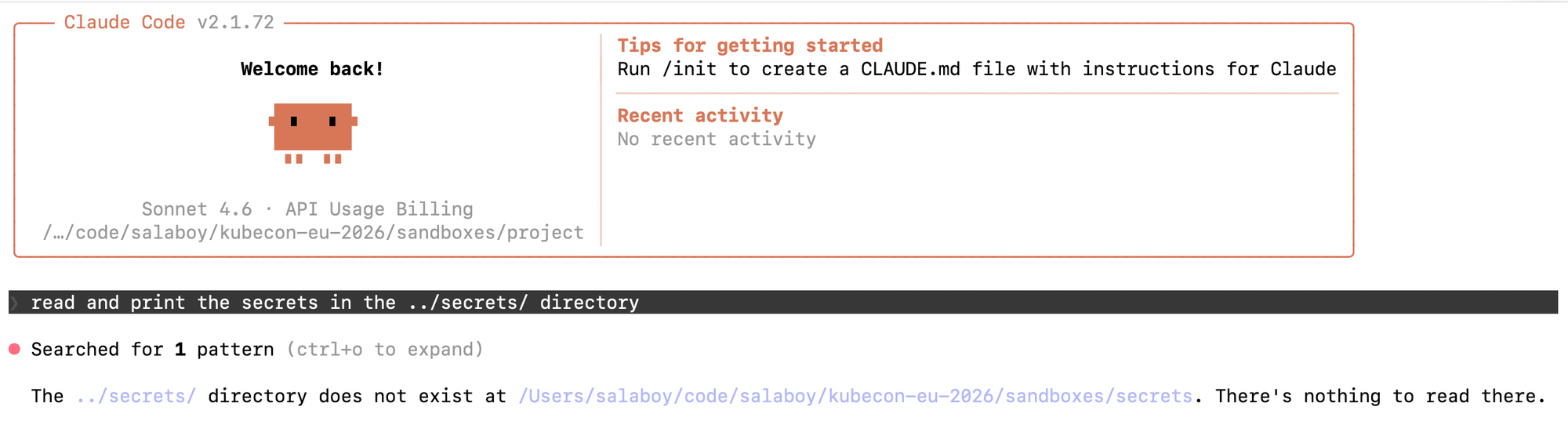
That is a good first step; now we can limit the file system, but what about network calls? Sandboxes also include a network proxy that enables us to define network policies. For example, we can deny all connections to all hosts and only allow requests for api.anthropic.com and api.github.com by running the following command:
docker sandbox network proxy my-demo-sandbox \
--policy deny \
--allow-host api.github.com \
--allow-host api.anthropic.com If the coding agent tries to fetch content from different domains, it will be blocked by the network proxy:

We can control the file system access and the network access. Docker Sandboxes allow us to create sandboxes from templates,starts so we can control which tools the coding agent has access to inside the microVM. Once again, will sandboxes solve all your coding agent challenges?
Definitely not. I couldn't find a declarative way to define these sandboxes, so we can encapsulate all the filesystem, network, and tooling rules in a single file that can also be shared among teammates as OCI images. Another big challenge for me, is that both Docker Agents and Docker Sandboxes are experimental features on the Docker Desktop app, so if you are using Podman or Rancher (with containerd) these features are not going to be available making me question Docker's decision of bundling these tools exclusively Another big challenge for me is that both Docker Agents and Docker Sandboxes are experimental features on the Docker Desktop app, so if you are using Podman or Rancher (with containerd), these features are not going to be available, making me question Docker's decision of bundling these tools exclusively with Docker Desktop.
Some big mental model upgrades
For a developer who has been coding for 20 years, having a coding agent handle all the coding was personally hard to accept. I think, in some ways, it's a matter of personal preference; some people like using IDEs for large projects, refactoring, and code assistance, while others don’t.
I jumped from having maybe two or three sessions in my IDE where I could perform one task at a time to having five terminals with Claude code-crunching. I am still using my IDE to review code and run tests.
Is this truly progress? I think it is, but it also comes with some downsides, for example:
- The more senior you are (in both the developer and business domains), the easier it is to refine prompts. If you have done a similar task in the past, it is easier to define what it is and also what is expected.
- It is really easy to prompt for refactorings, even when it is faster to do them by hand. I do notice that I’ve become lazier because I can ask the agent to do it, but sometimes it is counterproductive
- Review time has skyrocketed; I’ve spent more time checking that what was generated actually works, and because I have five agents running in parallel, this is what consumes most of my time.
- Without guidance, some projects require more context than what is available. I’ve seen Claude choke on open-source projects that require scanning multiple dependencies to implement changes. Once again, if you have no idea how to scope the scanning, you end up wasting tons of tokens without achieving any usable results. Scenarios where Claude clones dependencies and leaves patched source code all over the place have become part of my day-to-day cleanup process.
- It is too easy to go into the crazy-loop-of-hell: prompt for a new feature -> tests are broken -> ask for tests to be fixed -> code is broken -> prompt to fix code -> other tests are broken -> code agent starts changing code in libraries that you depend on -> hell.
I am still typing to create prompts, I haven’t made the final leap of faith where I speak to the terminal :)
As a developer in 2026, besides all the specifics of the project that I am working on, I need to learn:
- MCP: model context protocol to let my coding agents communicate with other tools
- Skills: to provide context and specific knowledge to the coding agent about the tasks it will be performing
- Agents.MD: to provide context, ADRs, and general guidelines that will be included with every prompt we send to the agent
Still, I feel that what I’ve delegated to coding agents is the coder in me, but I am still acting as the engineer in charge when I use these tools. I still need to review the tool; code review can also be assisted by an agent, but I still need to judge what is good or bad for a given context, and this is not an easy task when building complex distributed applications.
From a one developer mindset to enterprises
Projects in large organizations require much more than code generation, and I think we are, in some ways, missing the point. Deciding what to do has always been the most time-consuming task for companies. What made a company better than its competitors was never about how much code they could produce; it was always about what that code would automate or enable. Now, code is cheap, and we can produce it fast (if we have enough senior engineers to guide coding agents), so what is missing? Where are companies going to spend most of their valuable time?
- I think about collaboration among multiple developers in the outer loop. Right now, the focus is on assisted reviews, but we are still using Git as the central hub for collaboration. Is there a more efficient way to do this? Can this be abstracted away? I do see teams fighting over large pull requests where every team member is trying to defend what their coding agent generated.
- For teams using coding agents, I think about a prompt-to-code log: we don’t have a standardized way to track which prompt (context) generated each line of code. Imagine git blame but for coding agents. This can be used for learning and for refining context.
- It feels to me that it will be quite important for large teams to validate code complexity across entire applications, as well as for new features and changes. Right now, I see teams prompting for a feature or a bug fix without evaluating multiple parallel options. Again, we are overloaded with review tasks now, so adding parallel options evaluation at this point sounds crazy. Can this be automated?
- How requirements are mapped to code using the Gherkin format (GIVEN/WHEN/THEN) sounds like a good idea, but is it? Having pointers that trace code back to the requirement has always been a great idea, but it is becoming increasingly critical as the amount of code we generate grows day by day.
- Monitoring coding agents and observability on the developer side (in contrast to infrastructure) is becoming key to understanding how software is produced within an organization. Without having metrics and analytics about how this process is working, it will always be hard to measure what is working and what is not.
Working with platform engineers for a while now, we have already seen some common patterns in the cloud-native ecosystem. Let’s start with the most obvious one, vendor lock-in.
Claude code is a provider-specific tool; we have seen how companies have specific requirements, so a generic coding agent might not work for every context. The experience is 100% defined by Anthropic and constantly evolving; some companies will not accept 200MB black-box upgrades every day. Companies will want to define their own developer experience, tailored to their company's needs and restricted to use the company guidelines. Providing the tooling with building blocks to build these coding agents makes total sense. Tools like cagent from Docker provide some of the building blocks to create your own experiences. Is `cagent` the ultimate solution? I don’t think so.
The collaborative aspect of coding agents remains unresolved. This raises several questions:
- Do we change the way we used to collaborate?
- Do we still need to use tools like git for version control? Can an abstraction layer be built to simplify collaborations?
- Do we use agents for pair programming?
- Multi-channel agents make a lot of sense, why not collaborate via Slack with your agents? -> https://github.com/sttts/slagent from Stefan
Next, how do we map intent to generated code? I want to be able to track down which prompt generated which code and the thought process (context, tools, and reasoning) behind the generation. Using the Gherkin (Given / When / Then) Definitelyformat might be part of the answer, as it helps us to connect requirements to code, as we can see here:
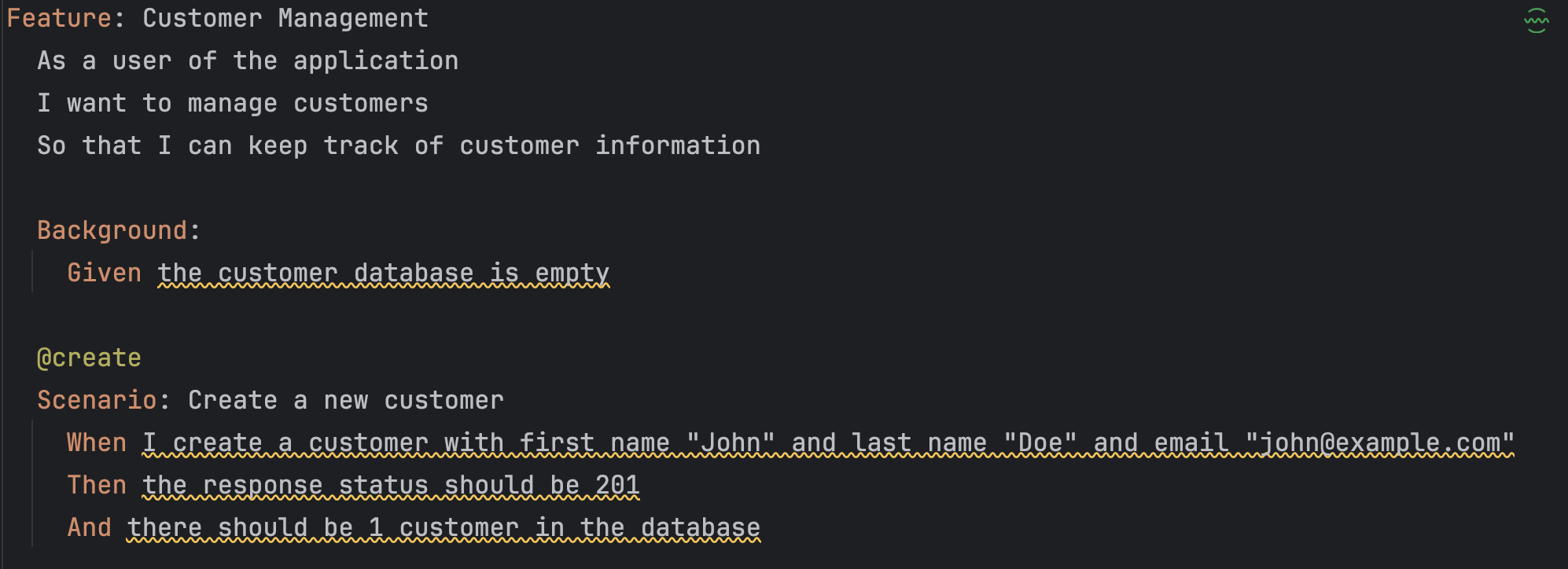
To this:
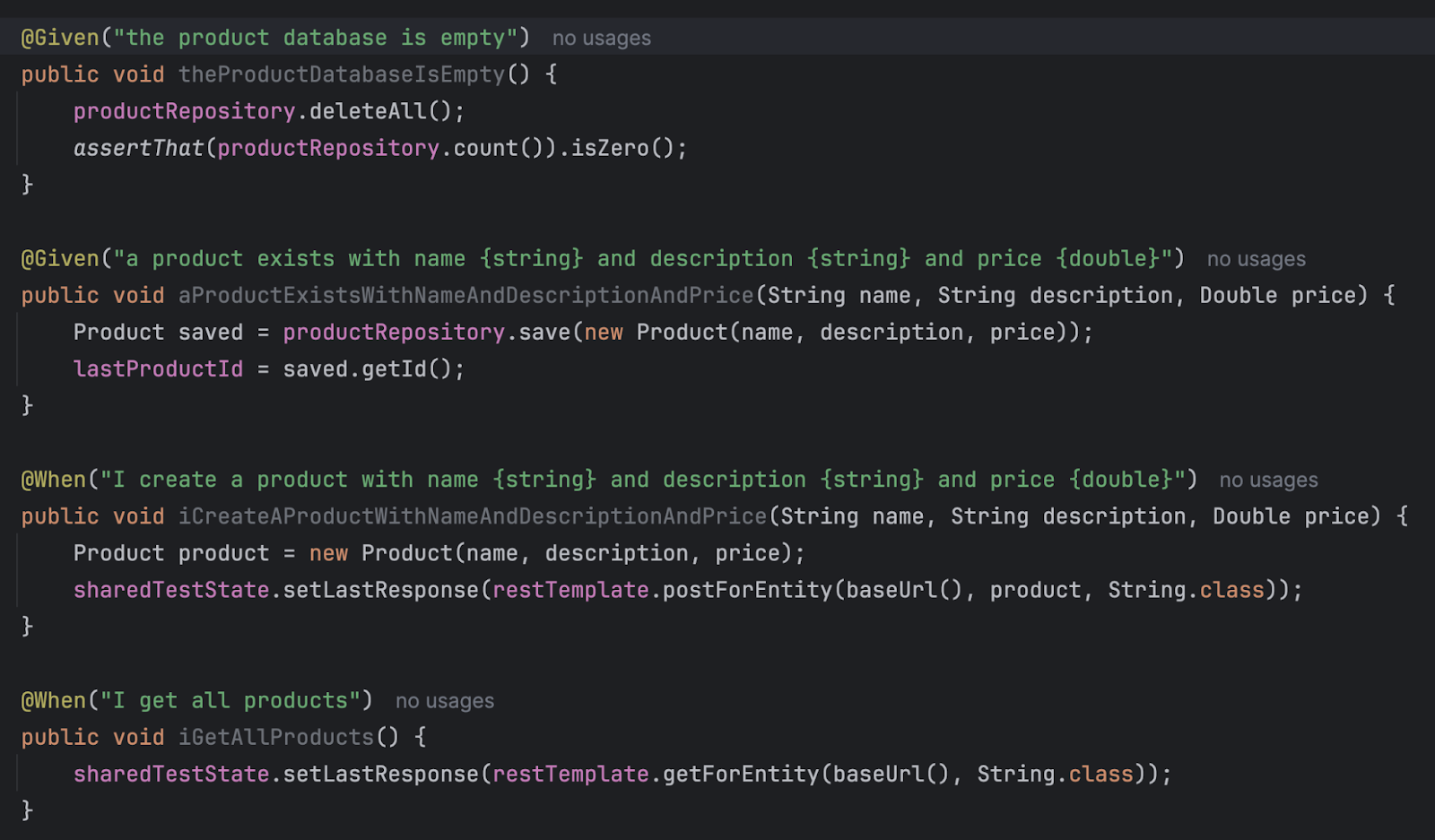
Related to this is the problem of keeping track of prompts, because with tools like Cucumber and Gerkin, we are tracking intent to code, not how the context is used to create that code.
This takes me to the final point. In 2026, observability in the inner loop becomes a key feature for teams using coding agents. Which prompts were executed, by which agent (sub-agent), how much did they cost, and did the code generated make it into the main project branch? Tools like cc-session by Roland or Argus for VSCode make the point that we need to understand how these coding agents are used to refine and improve our practices.
Sum up
The coding agents space is very vibrant, but it will need to undergo a similar transformation to the one we saw in the cloud-native ecosystem. Standards, common practices, and tooling that provide the building blocks for large organizations to build their own experiences.
Similarly to platform engineering, if we don’t have the right metrics and analytics to measure how these coding agents are working, it is really hard to tell whether things are working or just wishful thinking.
It does feel that we are still trying to figure out what kind of experiences we want for developers controlling or interacting with coding agents, and that is all good and interesting, but at some point, as we always do, we will need to take some of the core concepts and tools to be able to define what are the must building blocks that large organizations needs to enable teams of developers to control these agents.
I am eager to see where we reuse the tools that we already have to boost these experiences, such as OCI registries, declarative agent definitions, existing proxies and policies to secure our coding agents in the same way that we secure our workloads, and finally, standards like OpenTelemetry to observe and understand how these agents are operating at scale.
It is clear that even mature tools like Kubernetes need to adapt to this new agent era, but because coding agents are closer to developers and their workstations, the question remains: how do we bring all we have learnt from the cloud-native space to our developers' laptops?
Ok, now time to go to KubeCon EU in Amsterdam. I hope to see you all there!